
본 포스팅은 충남대 김현 교수님의 강의자료를 바탕으로 쓴 글입니다.
우선 MDP를 들어가기에 앞서, 간단히 강화학습이 무엇인지 알아보고자 한다.
강화학습이란 에이전트(A)가 어떤 환경(S)에서 누적보상(return)을 최대화할 수 있도록 행동(A)을 취하는 순차적 의사결정 문제를 해결하는 학습방법이다.
이 과정은 1. 환경을 관찰하고, 2. 관찰된 환경으로부터 현재 상태를 알아낸 후, 3. 최선의 행동을 결정하고, 4. 결과(보상)를 확인한 후, 5. 상태 정보를 변경하는 순서로 이루어진다.
행동을 취하게 되는 두 가지 방법이 있는데, 활용(Exploitation)과 탐색(Exploration)이다.
활용은 알고 있는 정보를 활용해 최선의 행동을 하는 것이고, 탐색은 알려지지 않은 행동을 시도해 새로운 경험을 얻는 것이다.
활용은 Short-term benefit, 탐색은 Long-term benefit이다.
활용에서, e-Greedy[e의 확률로 다른 행동 탐색], Upper Confidence Bound[선택 횟수 적은 a 탐색]의 방법이 있다.
1. K-Armed Bandit Problem
이는 위의 정의에서 말한 의사결정 문제 중 하나인데,
K개의 옵션을 가지고 있을 때, 무엇을 선택할지 불확실한 상황에서의 의사결정이다.
어찌됐든 하나의 행동을 취하게 될 것인데, 그때 예상되는 보상을 행동가치(Action Value)라 한다.
이에 대한 두 함수가 있다.
1) 행동가치함수 : Action a에 대한 모든 가능한 보상값들의 가중평균, q(a) = p(r|a)r의 합으로 나타내진다.
2) 행동선택 : 행동가치함수의 기댓값이 여럿 나올 텐데, 그 값이 가장 큰 Action a를 선택하는 것. 즉, q(a)를 최대화하는 a를 선택
2. Sequential Decision Making Problem
위에서 계속 순차적.. 이랬는데 순차적이라는 말이 정확히 뭘까?
이는 한 번의 행동으로 바뀌는 결과가 아니라, 순차적인, 차례대로의 행동에 따라 전체적인 결과가 바뀌는 것을 말한다.
따라서 이 순차적 의사결정 문제는 행동 하나 했을 때 주어지는 보상이 아니라 누적된 보상을 고려한다.
그럼 여기서 말하는 보상은 뭘까?
어떤 행동을 취했을 때 그 행동이 얼마나 좋은지 알려주는 scalar feedback signal, 즉 반응 신호인데 상수값인 것!
이 순차적 의사결정 과정은 보통 stochastic process에 기반한다. 이게 뭐냐면 매 시간마다 확률적으로 다른 결과를 얻는 것.
3. Markov Decision Process
그럼 이 stochastic process에서, 현재 상태에서 다음 상태 예측을 위해선 과거 상태들의 history가 필요한데,
과거의 모-든 상태를 알아야 하는 건 아니다. : 마코프 특성!
예를 들어,

이렇게 굴러가는 공이 있다면, 이전에 어떻게 굴러왔는지를 알아야 다음 방향을 예측할 수 있을 것이다.
이건 마코프 특성이 아니다!
마코프 특성은, 현재 상태가 주어졌을 때, 미래 상태의 조건부 확률분포는 과거 상태의 영향을 받지 않고 독립적으로, 현재 상태로만 결정되는 것이다.
예를 들어, 윷놀이에서 현재 말의 위치가 00일 때 다음 위치는? 이런 것을 말한다.
이 마코프 특성을 따르는 이산시간 확률과정을 마코프 프로세스라고 한다.
그리고 이 마코프 프로세스를 의사결정 문제에 이용한 모델을 마코프 결정 프로세스라고 한다.
MP와 MDP가 다른 점은, MP는 a&r의 영향을 받지 않는 것이다. 그림으로 보자면, 위는 MP, 아래는 MDP이다.
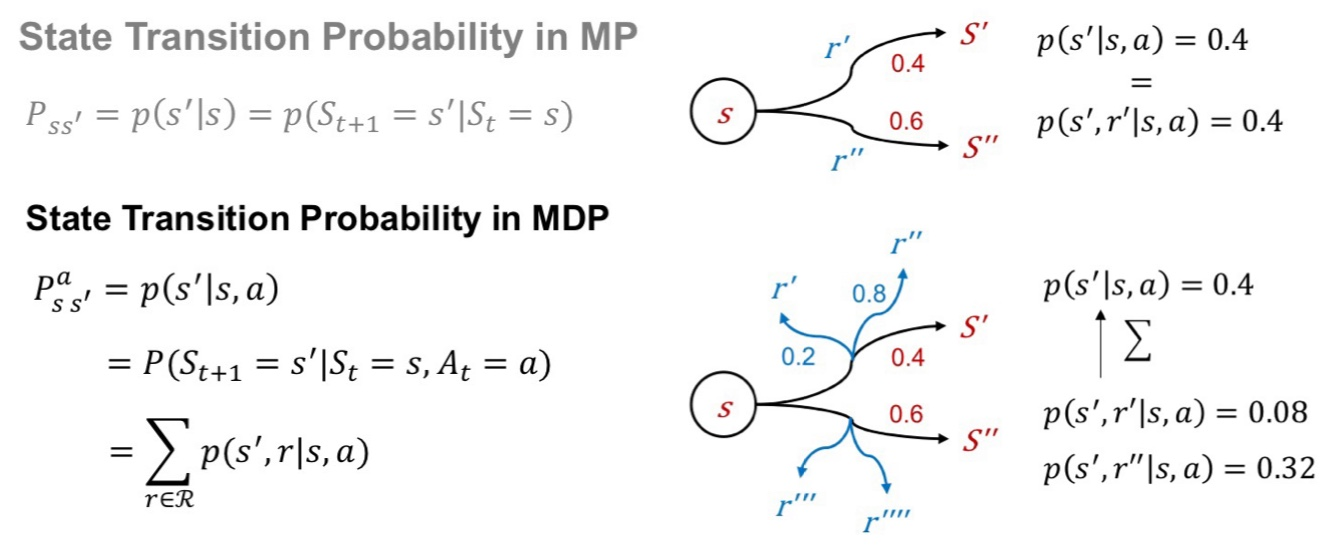
Markov Decision Process = Markov Process + action + reward, 즉
MDP는 <S, A, P, R, y(gamma)>로 구성된다.
State set, Action set, Probability matrix, Reward function, discount factor(gamma)이다.
여기서 p는
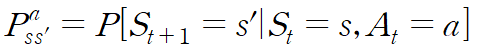
로 주어진다.
St에서 a를 취했을 때 St+1이 될 확률을 말한다.
4. 강화학습 모델, 구성
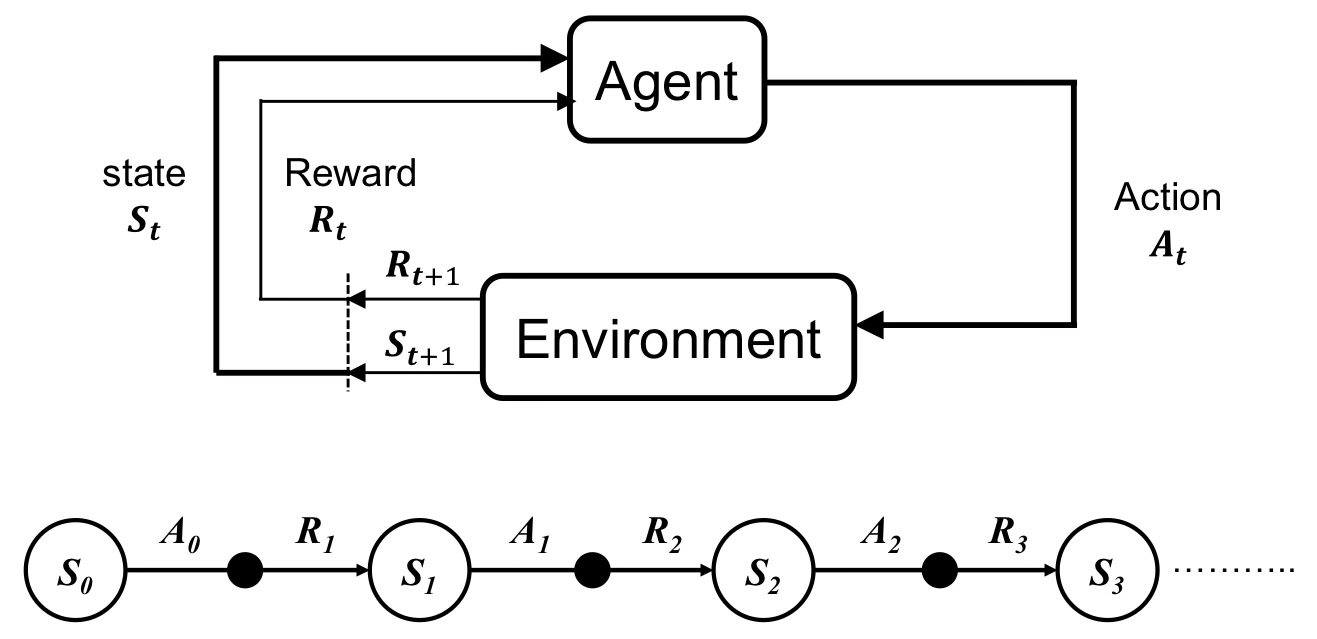
- Agent : action 선택의 주체
- State : [Environment state(환경 전체에 대한 정보) / Agent state(agent가 알고 있는 환경에 대한 정보) / Information state(agent가 의사결정 위해 사용하는 최소한의 정보-MDP에서는 과거 무시하고 현재만 고려하기에)]
- Reward : action이 얼마나 좋았는가
- Episode : 시작 상태부터 마지막 상태까지의 과정
- Return : Episode가 끝났을 때 받은 모든 Reward의 합, 이를 최대화하는 것이 목적
- 감가율 Discount factor : Return값을 유한하게 유지, 미래 불확실성 반영, 시간가치 반영
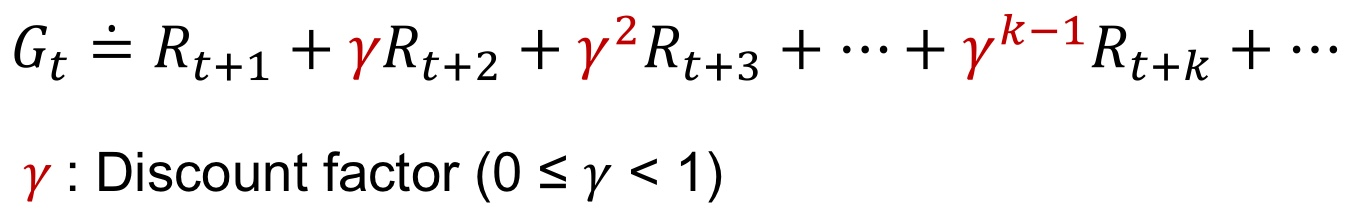
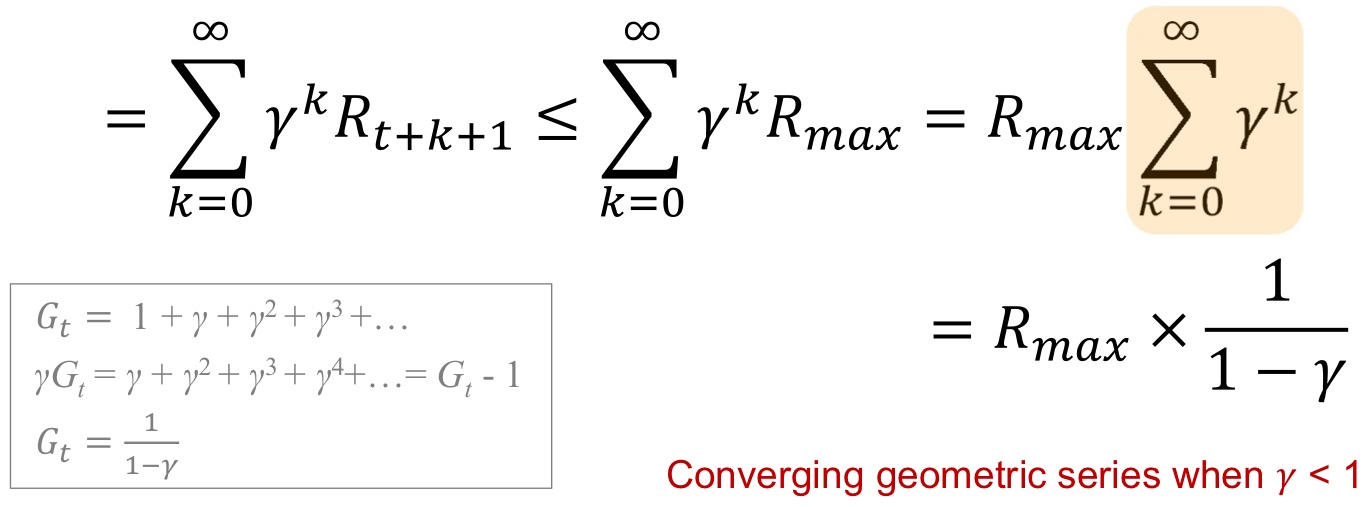
감가율은 0에 가까우면 agent가 즉각 보상에 관심을 둔다는 것이고, 1에 가까우면 agent가 미래 보상을 매우 크게 고려한다는 뜻!
'AI > 강화학습' 카테고리의 다른 글
| 시간차 학습(Temporal Difference Learning) (0) | 2024.10.24 |
|---|---|
| Monte Carlo Learning in RL (0) | 2024.10.24 |
| Dynamic Programming in RL (2) | 2024.10.23 |
| Value function & Bellman equation (0) | 2024.10.17 |
본 포스팅은 충남대 김현 교수님의 강의자료를 바탕으로 쓴 글입니다.
우선 MDP를 들어가기에 앞서, 간단히 강화학습이 무엇인지 알아보고자 한다.
강화학습이란 에이전트(A)가 어떤 환경(S)에서 누적보상(return)을 최대화할 수 있도록 행동(A)을 취하는 순차적 의사결정 문제를 해결하는 학습방법이다.
이 과정은 1. 환경을 관찰하고, 2. 관찰된 환경으로부터 현재 상태를 알아낸 후, 3. 최선의 행동을 결정하고, 4. 결과(보상)를 확인한 후, 5. 상태 정보를 변경하는 순서로 이루어진다.
행동을 취하게 되는 두 가지 방법이 있는데, 활용(Exploitation)과 탐색(Exploration)이다.
활용은 알고 있는 정보를 활용해 최선의 행동을 하는 것이고, 탐색은 알려지지 않은 행동을 시도해 새로운 경험을 얻는 것이다.
활용은 Short-term benefit, 탐색은 Long-term benefit이다.
활용에서, e-Greedy[e의 확률로 다른 행동 탐색], Upper Confidence Bound[선택 횟수 적은 a 탐색]의 방법이 있다.
1. K-Armed Bandit Problem
이는 위의 정의에서 말한 의사결정 문제 중 하나인데,
K개의 옵션을 가지고 있을 때, 무엇을 선택할지 불확실한 상황에서의 의사결정이다.
어찌됐든 하나의 행동을 취하게 될 것인데, 그때 예상되는 보상을 행동가치(Action Value)라 한다.
이에 대한 두 함수가 있다.
1) 행동가치함수 : Action a에 대한 모든 가능한 보상값들의 가중평균, q(a) = p(r|a)r의 합으로 나타내진다.
2) 행동선택 : 행동가치함수의 기댓값이 여럿 나올 텐데, 그 값이 가장 큰 Action a를 선택하는 것. 즉, q(a)를 최대화하는 a를 선택
2. Sequential Decision Making Problem
위에서 계속 순차적.. 이랬는데 순차적이라는 말이 정확히 뭘까?
이는 한 번의 행동으로 바뀌는 결과가 아니라, 순차적인, 차례대로의 행동에 따라 전체적인 결과가 바뀌는 것을 말한다.
따라서 이 순차적 의사결정 문제는 행동 하나 했을 때 주어지는 보상이 아니라 누적된 보상을 고려한다.
그럼 여기서 말하는 보상은 뭘까?
어떤 행동을 취했을 때 그 행동이 얼마나 좋은지 알려주는 scalar feedback signal, 즉 반응 신호인데 상수값인 것!
이 순차적 의사결정 과정은 보통 stochastic process에 기반한다. 이게 뭐냐면 매 시간마다 확률적으로 다른 결과를 얻는 것.
3. Markov Decision Process
그럼 이 stochastic process에서, 현재 상태에서 다음 상태 예측을 위해선 과거 상태들의 history가 필요한데,
과거의 모-든 상태를 알아야 하는 건 아니다. : 마코프 특성!
예를 들어,
이렇게 굴러가는 공이 있다면, 이전에 어떻게 굴러왔는지를 알아야 다음 방향을 예측할 수 있을 것이다.
이건 마코프 특성이 아니다!
마코프 특성은, 현재 상태가 주어졌을 때, 미래 상태의 조건부 확률분포는 과거 상태의 영향을 받지 않고 독립적으로, 현재 상태로만 결정되는 것이다.
예를 들어, 윷놀이에서 현재 말의 위치가 00일 때 다음 위치는? 이런 것을 말한다.
이 마코프 특성을 따르는 이산시간 확률과정을 마코프 프로세스라고 한다.
그리고 이 마코프 프로세스를 의사결정 문제에 이용한 모델을 마코프 결정 프로세스라고 한다.
MP와 MDP가 다른 점은, MP는 a&r의 영향을 받지 않는 것이다. 그림으로 보자면, 위는 MP, 아래는 MDP이다.
Markov Decision Process = Markov Process + action + reward, 즉
MDP는 <S, A, P, R, y(gamma)>로 구성된다.
State set, Action set, Probability matrix, Reward function, discount factor(gamma)이다.
여기서 p는
로 주어진다.
St에서 a를 취했을 때 St+1이 될 확률을 말한다.
4. 강화학습 모델, 구성
- Agent : action 선택의 주체
- State : [Environment state(환경 전체에 대한 정보) / Agent state(agent가 알고 있는 환경에 대한 정보) / Information state(agent가 의사결정 위해 사용하는 최소한의 정보-MDP에서는 과거 무시하고 현재만 고려하기에)]
- Reward : action이 얼마나 좋았는가
- Episode : 시작 상태부터 마지막 상태까지의 과정
- Return : Episode가 끝났을 때 받은 모든 Reward의 합, 이를 최대화하는 것이 목적
- 감가율 Discount factor : Return값을 유한하게 유지, 미래 불확실성 반영, 시간가치 반영
감가율은 0에 가까우면 agent가 즉각 보상에 관심을 둔다는 것이고, 1에 가까우면 agent가 미래 보상을 매우 크게 고려한다는 뜻!
'AI > 강화학습' 카테고리의 다른 글
| 시간차 학습(Temporal Difference Learning) (0) | 2024.10.24 |
|---|---|
| Monte Carlo Learning in RL (0) | 2024.10.24 |
| Dynamic Programming in RL (2) | 2024.10.23 |
| Value function & Bellman equation (0) | 2024.10.17 |