
딥러닝
2024.05.20 - [기계학습] - 머신러닝과 딥러닝의 차이
앞 포스팅에서 말했듯, 딥러닝은 히든층이 3층 이상인 경우를 말한다.
보통 이런 딥러닝 모델이 학습할 때에는 Loss function을 최소화하기 위해 최적화 알고리즘을 적용시킨다.
여기서 Loss function은 예측값과 실제값간의 오차값을 뜻하는 함수이다.
Optimization은 그 Loss function을 최소화시키는 모델의 파라미터(인자)를 찾는 과정을 말한다.
이 Optimization 알고리즘 중 가장 기본적인 알고리즘은 Gradient Descent, 경사하강법이다.
가중치가 W일 때 손실함수를 loss(W)라고 나타낸다면, 기울기는 이 손실함수를 미분한 것인데, 이를 이용하는 것이다.
역전파(Backpropagation)를 통해 각 가중치들의 기울기 구하기 가능.
역전파란?
목표값과 내 모델의 출력의 차이를 구하고, 그 오차를 앞으로 전파해가며 파라미터를 갱신.
그렇다면 순전파란?
입력값 넣어서 파라미터 통과해서 출력값 계산.
딥러닝 모델을 구현할 때는 고려사항이 많은데..
따라서 이 모델을 쉽게 구현하고 사용하도록 다양한 프레임워크가 제공됨.
KERAS, torch, TensorFlow, Chainer, Caffe, CNTK 등....
이 중 TensorFlow-PyTorch-Keras 순으로 많이 사용되고 빨리 성장되었다.
TensorFlow
유연, 효율, 확장성. 대형 클러스터 컴퓨터부터~ 스마트폰까지 다양한 디바이스에서 동작한다.
"텐서" - 다차원 배열로 나타내는 데이터. 1D(vector), 2D(array), 3D(육면체 느낌)
- 상수 텐서(Constant Tensor) : 고정된 값. 문자/숫자
import tensorflow as tf
tensor_A = tf.constant(value, dtype = "반환 tensor 타입", shape = "Tensor의 차원", name = "텐서 이름")
tensor_B = tf.zeros(shape, dtype, name)
tensor_C = tf.ones(shape, dtype, name)- 시퀀스 텐서
tensor_D = tf.linspace(start, stop, num, name) ##(시작값, 끝값, 생성할 데이터 개수, 텐서 이름)
tensor_E = tf.range(start, limit, delta, name) ##(시작값, 끝값, 증가량, 텐서 이름)- 변수 텐서
tensor_F = tf.Variable(initial_value, dtype, name) ##(초기값, 반환 tensor 타입, 텐서 이름)
"플로우" - 데이터의 흐름. 그래프를 따라 데이터가 노드를 거쳐 흘러가는..
모델 구현 순서
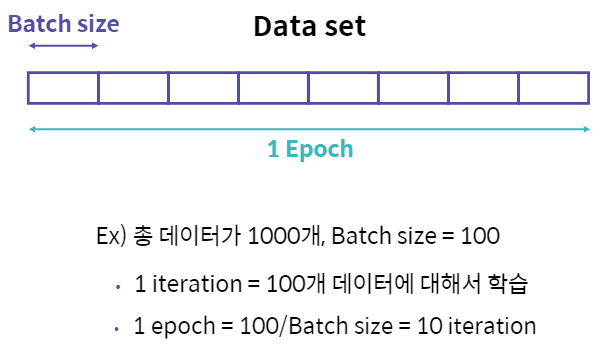
1. 데이터셋 준비
Epoch : 학습 범위
Batch : 나눠진 데이터 셋(mini-batch라고도 함)
2. 딥러닝 모델 구축
고수준 API Keras 이용. 텐서플로우의 패키지 중 하나.
tf.keras.models.Sequential()
tf.keras.layers.Dense(units, activation) #units:레이어 안 노드 수, activation:적용할 활성화함수
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_dim=2, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
same_model = tf.keras.models.Sequential()
same_model.add(tf.keras.layers.Dense(10, input_dim = 2, activation = 'sigmoid'))
same_model.add(tf.keras.layers.Dense(10, activation = 'sigmoid'))
same_model.add(tf.keras.layers.Dense(1, activation = 'sigmoid'))
위와같이 모델을 처음부터 층을 만들어 생성하거나, 아니면 모델을 만들어두고 층을 추가할 수도 있다.
3. 모델 학습시키기
model.compile(optimizer='SGD', loss='mean_squared_error')
## optimizer : 모델 학습 최적화 방법
## loss : 손실 함수 설정
model.fit(x, y)
## X : 학습 데이터, y : 학습 데이터 label, verbose : (0 - 출력x, 1 - 상세히 출력, 2 - 요약출력)
model.fit(dataset, epochs = 100, batch_size = 500, validation_data = (test_x, test_y), verbose = 0)
4. 평가 및 예측
model.evaluate(x, y) ## test data
model.predict(x) ## 진짜 예측할 data
참고 : LG Aimers
'AI > 기계학습' 카테고리의 다른 글
| Tensorflow 선형회귀/비선형회귀 (0) | 2024.05.27 |
|---|---|
| 딥러닝 학습의 문제점 (0) | 2024.05.22 |
| AND, OR, NAND, NOR gate in python (0) | 2024.05.20 |
| 퍼셉트론 (0) | 2024.05.20 |
| 머신러닝과 딥러닝의 차이 (0) | 2024.05.20 |