
본 포스팅은 충남대 고영준 교수님의 강의자료를 바탕으로 작성한 글입니다.
Attention
Attention에서는 query, key, value가 필수이다.
일단 key와 value는 pair한 관계이다.
attention은 우리가 어디에 집중해야할지를 알려준다.
그럼 그 가중치는 어떻게 구할까?
v의 중요도인 a를 계산하기 위해 우리는 v의 짝인 k를 사용한다.
input(query)와 key의 유사도에 기반해서, key가 query에 더 유사할 수록, attention 가중치는 커진다.
그럼 q와 k의 유사도를 고려하면 되는 것!
그럼 저 유사도는 어떻게 결정할까?
우린 저 둘의 내적을 계산한다.
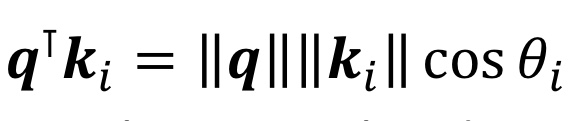
이걸 기억하면 두 벡터의 방향이 비슷할 수록 내적이 커진다는 사실을 인지할 수 있다.
그럼 이제 attention scores를 다시 쓸 수 있다.
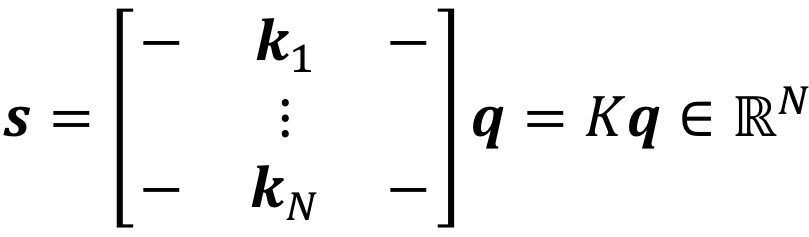
이렇게 말이다! 여기서 s, k, q는 모두 bold체이므로 벡터이다.
그런데 여기서 이 kq는 attention 가중치의 조건을 만족하진 않는다. 이건 단지 attention score!
attention weight의 조건은, 모든 가중치의 합이 1이며, 각 가중치는 0이상이어야 하는 것!
그럼 이걸 어떻게 바꿀까?
저 score에 softmax function을 적용하는 것이다!
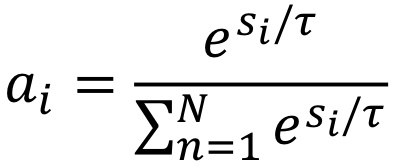
이렇게 말이다. 여기서 저 t처럼 생긴 문자는 tau인데, 이는 softmax를 통제하기 위한 파라미터이며, 여기선 sqrt(d)로 정했다.
그럼 최종적으로 나타내면,
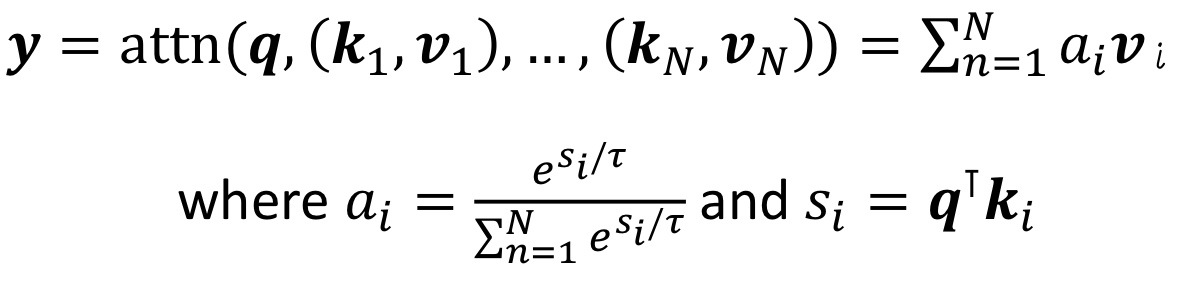
이게 될 것이고, 이를 다시 간단히 써본다면
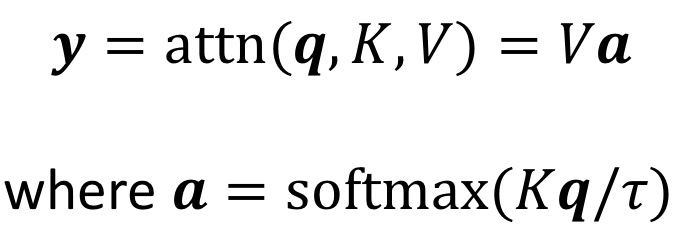
가 될 것이다.
결과적으로 요약하여 표현하자면,
value에 대한 가중치 a를 구할 것인데, 이때 value의 쌍인 key를 사용할 것이다.
그 key와, 우리의 입력인 query 사이 유사도를 구하면 이게 attention score이고,
이를 가중치처럼 만들기 위해 softmax를 적용시켜 attention weight를 구한다.
그럼 이 attention weight와 value를 가중합하여 output을 구할 수 있다.
Self-Attention
위 attention 메커니즘에 기반해서, 새로운 작동을 정의한 것.
Xi를 input이라 하고, 우린 Q, K, V를 얻는다.
이 Q, K, V는 각각 Q=W_q*X, K = W_k*X, V=W_v*X 이다.
각 가중치들은 행렬로 나타나고, 이들은 선형 레이어들로 표현된다.
Linear classifier
Img -> f(x, W) -> #class 개의 class score
셀프어텐션은 입력을 출력으로 바꿀 때, 입력들 간의 유사성을 고려하는 과정으로 생각할 수 있다.
예를 들어 보겠다. 일단 각 Q, K, V를 모두 이렇게 생각해본다.
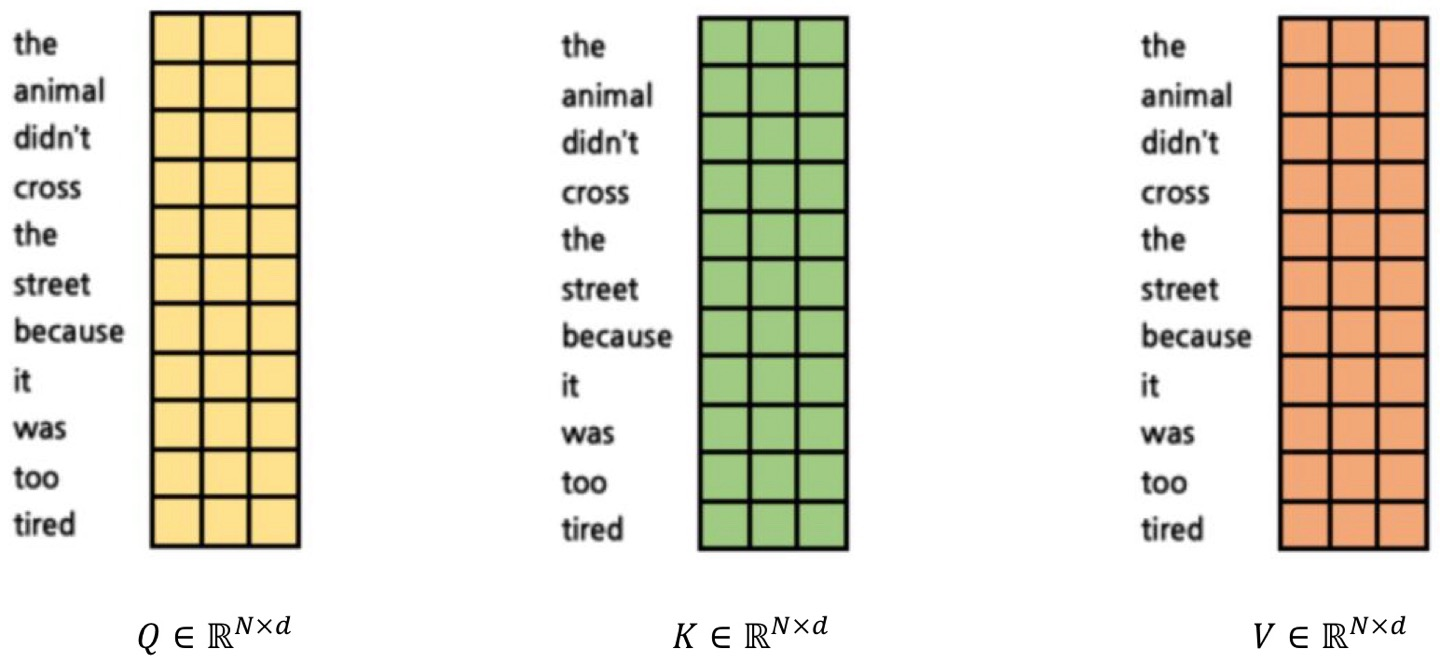
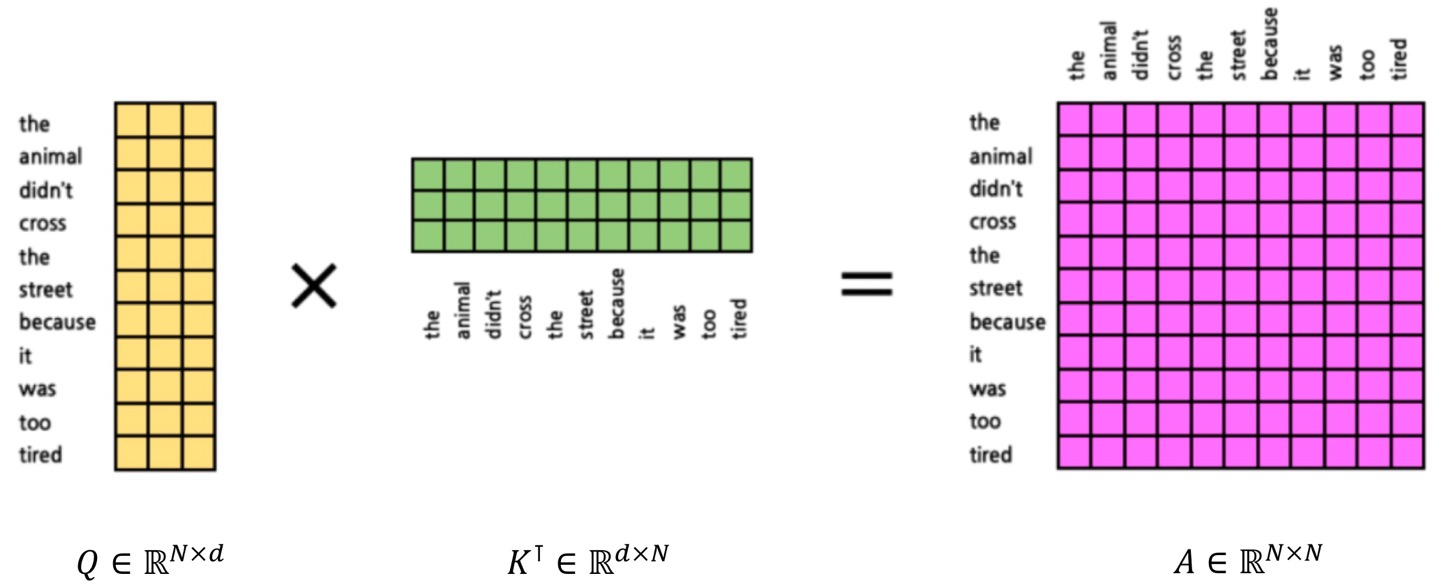
그 후, attention score의 계산을 위해 q와 k를 곱해서 a를 만든다.
이제 그럼 attention weight 계산을 위해 softmax를 하고, 이 가중치를 value와 곱해서 Y를 내놓는 것!
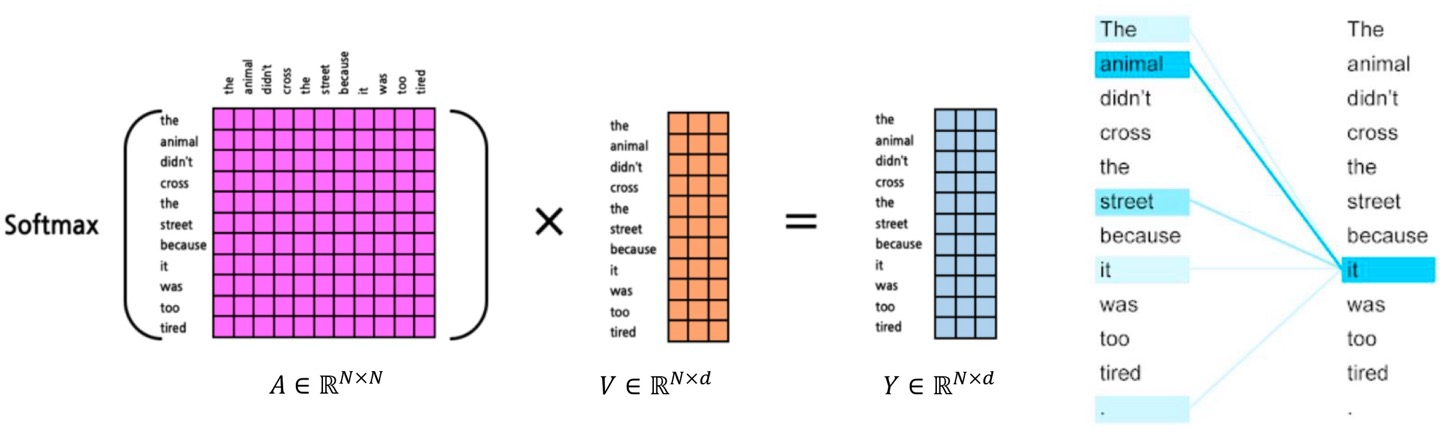
이는 RNN과는 다르게, 입력에 대한 의존성을 위한 많은 층이 필요하진 않다.
Multi-Head Self-Attention (MSA)
이건 집단 conv 기반 아이디어이다.
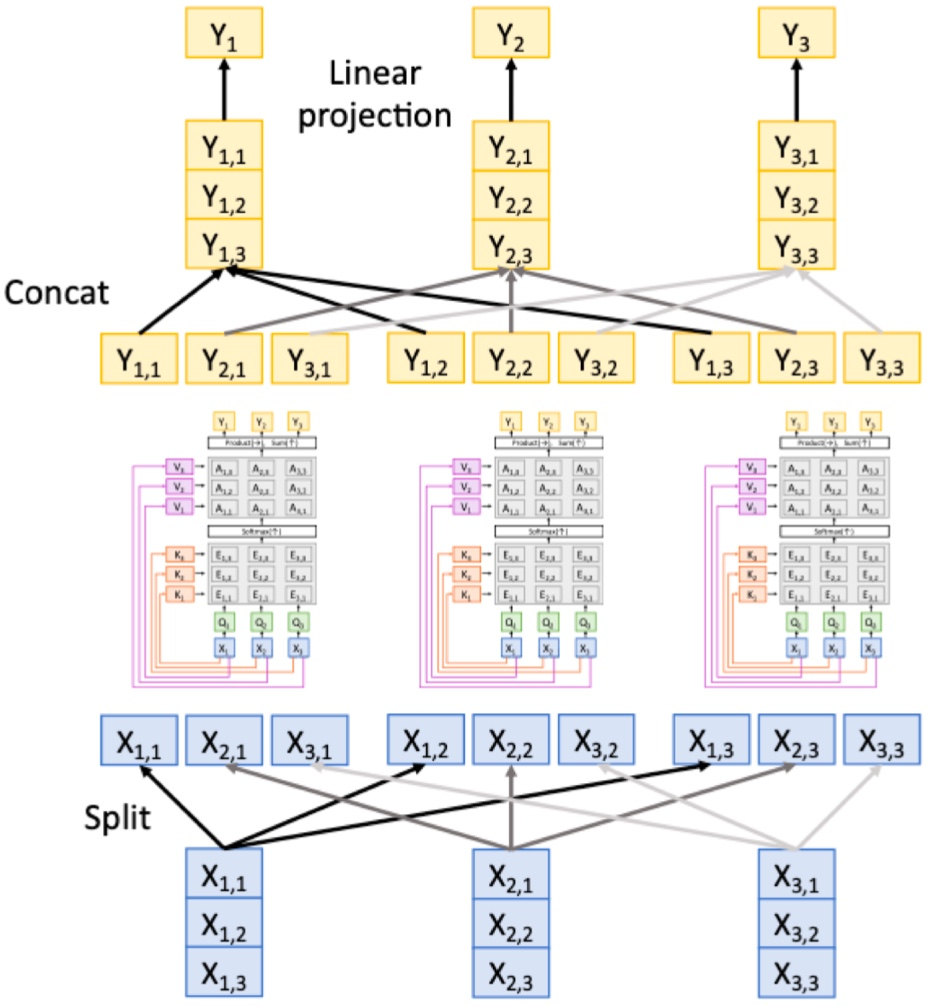
이렇게 쓰는 것~
어텐션 메커니즘의 확장성
- 인풋 크기가 커진다고 해서 파라미터 개수가 많아지진 않는다
- transformer 아키텍처를 이미지 및 오디오 같은 다른 도메인으로 확장 가능
Positional encoding
이건 데이터의 위치 정보를 더해주는 것인데,
장 : 위치와 상관없이 정보 전달 가능
단 : 입력 순서를 고려하지 않음 (위치정보가 중요함에도 불구하고) -> 입력 인덱스 나타내는 특징을 신경망에 제공하면 해결 가능
Transformer block
구조
멀티헤드 셀프어텐션이 입력의 가중합을 계산
입력의 가중합으로 MLP는 비선형 변환 수행
각 단계에서 residual connection과 layer 정규화 기술이 훈련 안정성을 위해 추가됨
종류
1. Post-norm transformer block
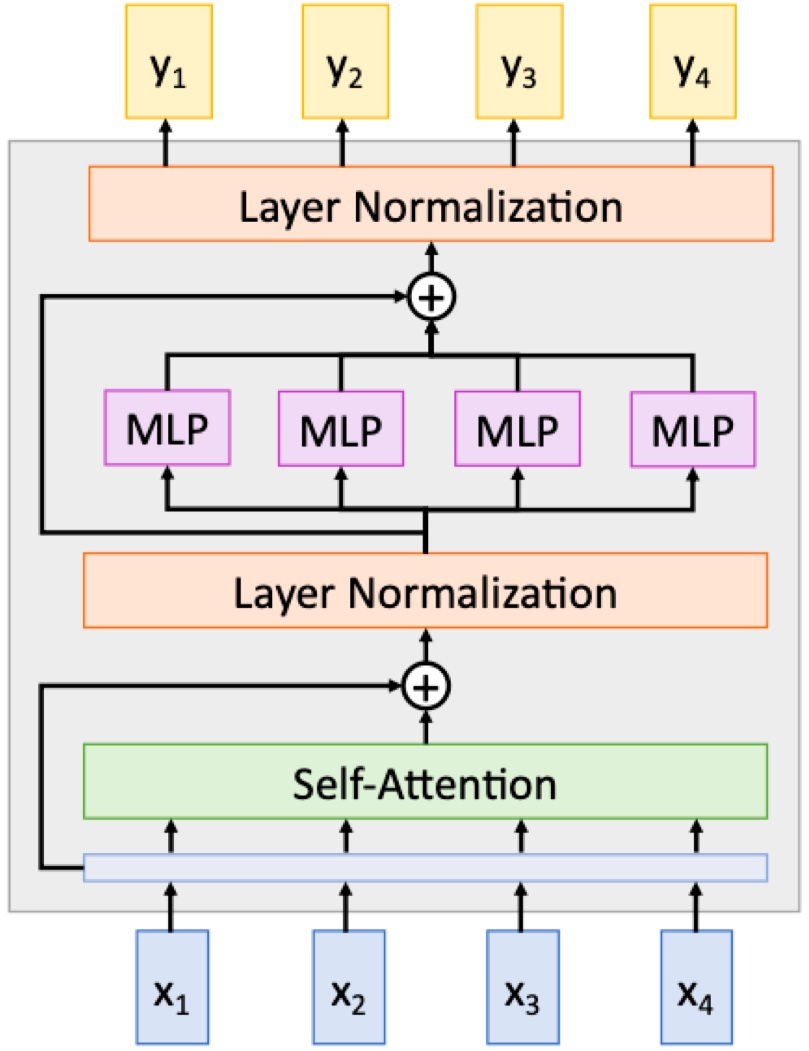
이게 보통 오리지널이고, residual connection 뒤에 층 정규화 위치
2. Pre-norm transformer block
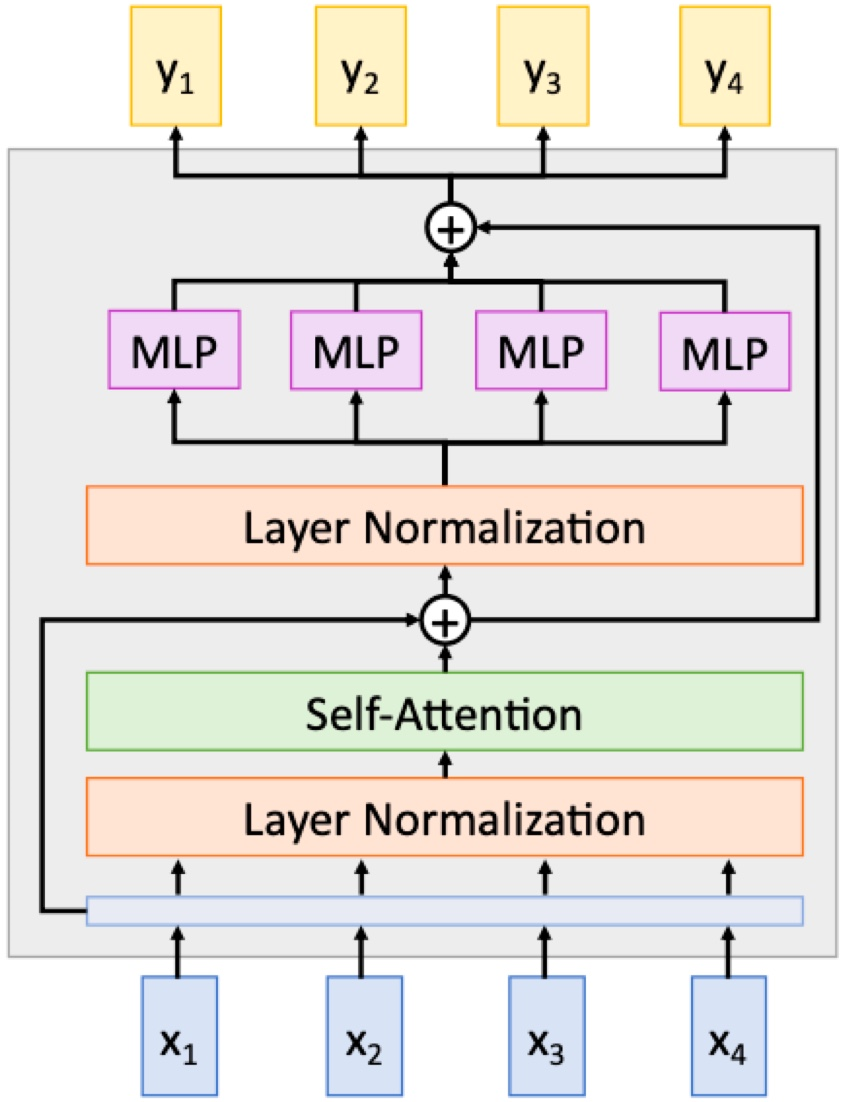
층 정규화가 residual connection 안에 위치
실습에서 주로 쓰이고, 훈련이 더 안정적임.
그리고 이 transformer block들이 sequence로 연결된 것이 transformer!
block 개수가 깊이, Q, K, V의 차원이 width...
Cross Attention
두 개의 다른 입력의 상관관계 계산을 위해 사용. ex) 문장1, 문장2
하나의 입력은 Q로, 나머지 하나의 입력은 V&K
Self Attention과 다른 것은, Q에 들어오는 입력과 V&K에 들어오는 입력이 다르다는 것!
Vision Transformer
- input tensor : #token * hidden embedding dim
그럼 Img는 H*W*3인데, 이걸 어떻게 N*C로 바꿀까?
1. 일단 이미지의 token은, 이미지를 패치별로 나눠서 각 패치를 모두 token으로 볼 수 있다.
2. 그 패치를 가지고 네트워크 초기 단계 생성 (Patchify stem)
3. Input인 patch에 대해 이를 vector로 변경 (Token embedding)
4. 각 패치의 공간벡터 생성 (Position embedding)
5. Transformer Encoder
6. Class token 생성
7. Classification head로 예측 클래스 분류
8. 예측 결과 출력
이 비전 트랜스포머를 이용한 모델은 ViT인데, 관계는 아래와 같다.
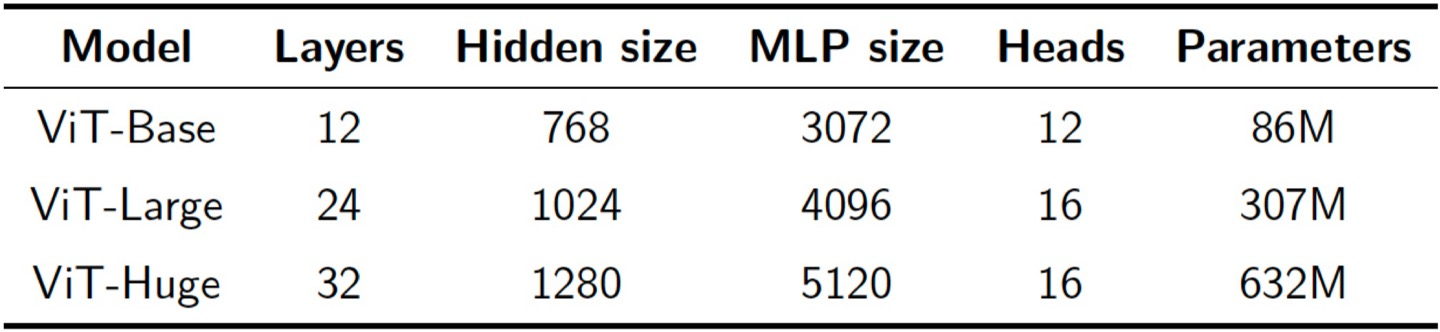
이 ViT 모델은 ImageNet 데이터에선 과적합 됐지만, 더 큰 데이터에서는 훨씬 좋다.
저 ImageNet1K 데이터에서는 ViT보다 ConvNet(BiT)가 좋은데, 그 이유는 뭘까?
- ConvNet은 공간적 정보를 포함한다. ViT는 공간 정보가 없으므로 데이터로부터 그거까지 학습해야 하기에 큰 데이터셋 필요.
- ViT는 파라미터가 많아 작은 데이터셋에는 과적합되기 쉽다.
MLP Mixer
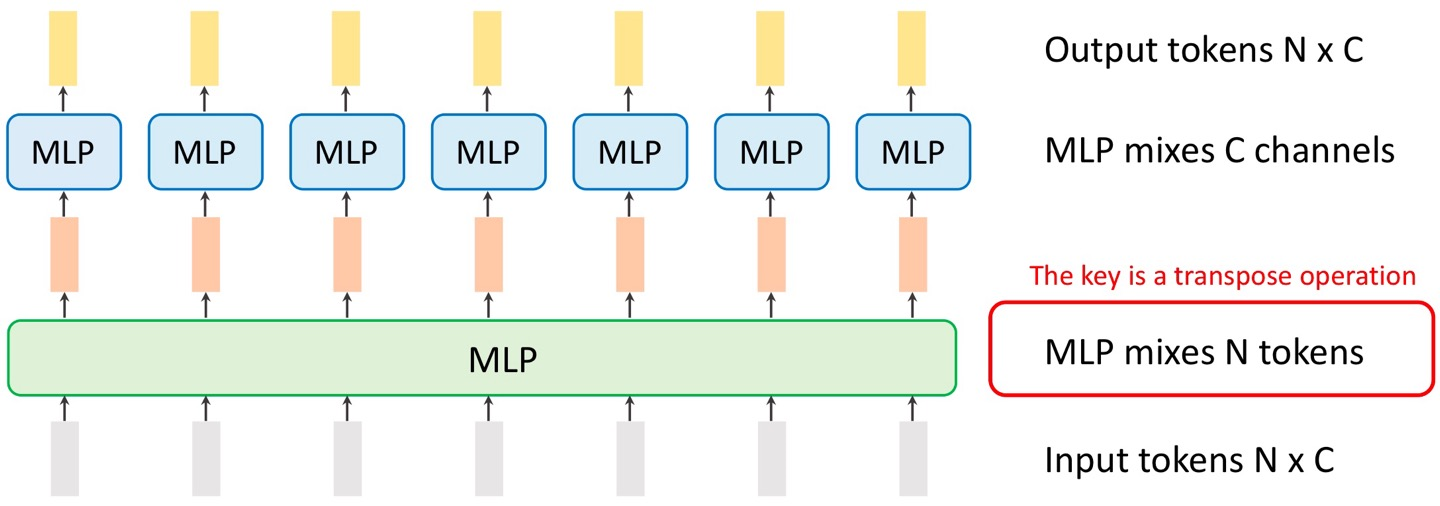
저 커다란 MLP 부분이 원래는 MSA인데, 그걸 MLP로 바꾼 것.
즉 모든 구조가 MLP로 이루어진 것!
원래 10*10*300 구조를 VGG 초창기 땐 (30000, )로 바꿨었는데, 이젠 100*300으로 바꾼다.
Vision Tasks
Two-stage detectors에선, box N개를 예측해서 그 box가 객체인지 아닌지 판별한다.
그치만 충분히 많은 고정 N예측을 높은 신뢰도로 생성할 수 있다면 region proposal이 필요할까?
Detection with Transformer(DETR)
1. 웬만하면 이미지에서 객체가 100개를 안 넘기 때문에, 일단 N=100으로 정한다.
2. 그리고 backbone을 CNN을 써서 이미지 특성을 추출하고,
3. positional encoding을 찾아서
4. backbone과 positional encoding을 합해서 Transformer encoder를 통과시킨다.
각 transformer block은 MSA와 FFN이 있다.
5. transformer decoder를 통과시킨다.
6. prediction head를 통과시킨다.
'AI > 컴퓨터비전' 카테고리의 다른 글
| Object Detection (1) | 2024.12.16 |
|---|---|
| Image Warping (new!) (0) | 2024.12.16 |
| Image Alignment (1) | 2024.12.16 |
| SIFT (0) | 2024.12.16 |
| Image Classification (0) | 2024.12.15 |
본 포스팅은 충남대 고영준 교수님의 강의자료를 바탕으로 작성한 글입니다.
Attention
Attention에서는 query, key, value가 필수이다.
일단 key와 value는 pair한 관계이다.
attention은 우리가 어디에 집중해야할지를 알려준다.
그럼 그 가중치는 어떻게 구할까?
v의 중요도인 a를 계산하기 위해 우리는 v의 짝인 k를 사용한다.
input(query)와 key의 유사도에 기반해서, key가 query에 더 유사할 수록, attention 가중치는 커진다.
그럼 q와 k의 유사도를 고려하면 되는 것!
그럼 저 유사도는 어떻게 결정할까?
우린 저 둘의 내적을 계산한다.
이걸 기억하면 두 벡터의 방향이 비슷할 수록 내적이 커진다는 사실을 인지할 수 있다.
그럼 이제 attention scores를 다시 쓸 수 있다.
이렇게 말이다! 여기서 s, k, q는 모두 bold체이므로 벡터이다.
그런데 여기서 이 kq는 attention 가중치의 조건을 만족하진 않는다. 이건 단지 attention score!
attention weight의 조건은, 모든 가중치의 합이 1이며, 각 가중치는 0이상이어야 하는 것!
그럼 이걸 어떻게 바꿀까?
저 score에 softmax function을 적용하는 것이다!
이렇게 말이다. 여기서 저 t처럼 생긴 문자는 tau인데, 이는 softmax를 통제하기 위한 파라미터이며, 여기선 sqrt(d)로 정했다.
그럼 최종적으로 나타내면,
이게 될 것이고, 이를 다시 간단히 써본다면
가 될 것이다.
결과적으로 요약하여 표현하자면,
value에 대한 가중치 a를 구할 것인데, 이때 value의 쌍인 key를 사용할 것이다.
그 key와, 우리의 입력인 query 사이 유사도를 구하면 이게 attention score이고,
이를 가중치처럼 만들기 위해 softmax를 적용시켜 attention weight를 구한다.
그럼 이 attention weight와 value를 가중합하여 output을 구할 수 있다.
Self-Attention
위 attention 메커니즘에 기반해서, 새로운 작동을 정의한 것.
Xi를 input이라 하고, 우린 Q, K, V를 얻는다.
이 Q, K, V는 각각 Q=W_q*X, K = W_k*X, V=W_v*X 이다.
각 가중치들은 행렬로 나타나고, 이들은 선형 레이어들로 표현된다.
Linear classifier
Img -> f(x, W) -> #class 개의 class score
셀프어텐션은 입력을 출력으로 바꿀 때, 입력들 간의 유사성을 고려하는 과정으로 생각할 수 있다.
예를 들어 보겠다. 일단 각 Q, K, V를 모두 이렇게 생각해본다.
그 후, attention score의 계산을 위해 q와 k를 곱해서 a를 만든다.
이제 그럼 attention weight 계산을 위해 softmax를 하고, 이 가중치를 value와 곱해서 Y를 내놓는 것!
이는 RNN과는 다르게, 입력에 대한 의존성을 위한 많은 층이 필요하진 않다.
Multi-Head Self-Attention (MSA)
이건 집단 conv 기반 아이디어이다.
이렇게 쓰는 것~
어텐션 메커니즘의 확장성
- 인풋 크기가 커진다고 해서 파라미터 개수가 많아지진 않는다
- transformer 아키텍처를 이미지 및 오디오 같은 다른 도메인으로 확장 가능
Positional encoding
이건 데이터의 위치 정보를 더해주는 것인데,
장 : 위치와 상관없이 정보 전달 가능
단 : 입력 순서를 고려하지 않음 (위치정보가 중요함에도 불구하고) -> 입력 인덱스 나타내는 특징을 신경망에 제공하면 해결 가능
Transformer block
구조
멀티헤드 셀프어텐션이 입력의 가중합을 계산
입력의 가중합으로 MLP는 비선형 변환 수행
각 단계에서 residual connection과 layer 정규화 기술이 훈련 안정성을 위해 추가됨
종류
1. Post-norm transformer block
이게 보통 오리지널이고, residual connection 뒤에 층 정규화 위치
2. Pre-norm transformer block
층 정규화가 residual connection 안에 위치
실습에서 주로 쓰이고, 훈련이 더 안정적임.
그리고 이 transformer block들이 sequence로 연결된 것이 transformer!
block 개수가 깊이, Q, K, V의 차원이 width...
Cross Attention
두 개의 다른 입력의 상관관계 계산을 위해 사용. ex) 문장1, 문장2
하나의 입력은 Q로, 나머지 하나의 입력은 V&K
Self Attention과 다른 것은, Q에 들어오는 입력과 V&K에 들어오는 입력이 다르다는 것!
Vision Transformer
- input tensor : #token * hidden embedding dim
그럼 Img는 H*W*3인데, 이걸 어떻게 N*C로 바꿀까?
1. 일단 이미지의 token은, 이미지를 패치별로 나눠서 각 패치를 모두 token으로 볼 수 있다.
2. 그 패치를 가지고 네트워크 초기 단계 생성 (Patchify stem)
3. Input인 patch에 대해 이를 vector로 변경 (Token embedding)
4. 각 패치의 공간벡터 생성 (Position embedding)
5. Transformer Encoder
6. Class token 생성
7. Classification head로 예측 클래스 분류
8. 예측 결과 출력
이 비전 트랜스포머를 이용한 모델은 ViT인데, 관계는 아래와 같다.
이 ViT 모델은 ImageNet 데이터에선 과적합 됐지만, 더 큰 데이터에서는 훨씬 좋다.
저 ImageNet1K 데이터에서는 ViT보다 ConvNet(BiT)가 좋은데, 그 이유는 뭘까?
- ConvNet은 공간적 정보를 포함한다. ViT는 공간 정보가 없으므로 데이터로부터 그거까지 학습해야 하기에 큰 데이터셋 필요.
- ViT는 파라미터가 많아 작은 데이터셋에는 과적합되기 쉽다.
MLP Mixer
저 커다란 MLP 부분이 원래는 MSA인데, 그걸 MLP로 바꾼 것.
즉 모든 구조가 MLP로 이루어진 것!
원래 10*10*300 구조를 VGG 초창기 땐 (30000, )로 바꿨었는데, 이젠 100*300으로 바꾼다.
Vision Tasks
Two-stage detectors에선, box N개를 예측해서 그 box가 객체인지 아닌지 판별한다.
그치만 충분히 많은 고정 N예측을 높은 신뢰도로 생성할 수 있다면 region proposal이 필요할까?
Detection with Transformer(DETR)
1. 웬만하면 이미지에서 객체가 100개를 안 넘기 때문에, 일단 N=100으로 정한다.
2. 그리고 backbone을 CNN을 써서 이미지 특성을 추출하고,
3. positional encoding을 찾아서
4. backbone과 positional encoding을 합해서 Transformer encoder를 통과시킨다.
각 transformer block은 MSA와 FFN이 있다.
5. transformer decoder를 통과시킨다.
6. prediction head를 통과시킨다.
'AI > 컴퓨터비전' 카테고리의 다른 글
| Object Detection (1) | 2024.12.16 |
|---|---|
| Image Warping (new!) (0) | 2024.12.16 |
| Image Alignment (1) | 2024.12.16 |
| SIFT (0) | 2024.12.16 |
| Image Classification (0) | 2024.12.15 |