
본 포스팅은 충남대 이종률 교수님의 강의자료를 바탕으로 작성한 글입니다.
Vector Space Model
concept 벡터로 문서를 나타내는 법
- 각 concept는 하나의 차원을 정의한다.
- k concept는 높은 차원의 공간을 정의한다.
- 벡터의 요소는 concept 가중치에 해당한다.
이 concept 공간에서의 벡터간 거리는 문서간 관계를 나타낸다.
뭐 만약 축이 스포츠, 교육, 금융 이라면 (주제) 각 문서가 투영되는 것을 통해 그 문서는 어느 주제에 관련있는지 볼 수 있다.

이런 식으로 말이다.
근데 이제 이 VS모델이 나타내지 않는 것이 있는데, 그게 뭐냐면
- 기본 컨셉을 어떻게 잡는가 (concept은 직교하는 것으로 가정)
- 가중치를 어떻게 할당하는가 (가중치는 concept이 문서를 얼마나 잘 특성화하는지를 뜻함)
- 거리 메트릭을 어떻게 정의하는가
그렇다면 좋은 기본 컨셉은 무엇일까?
- 직교하는(선형 독립 기본 벡터들-의미상 겹치지 않는, 모호하지 않은)
- 가중치가 자동으로, 정확하게 할당되는
- 이미 해결책이 주어진(BoW, Topics)
Bag-of-Words(BOW)
- 문서를 단순히 단어들의 집합으로 표현
- 단어 순서는 무시하고 각 단어의 등장 빈도만 고려
ex)

Zipf's Law
단어 빈도는 단어의 순위에 반비례한다는 것.
k가 등수, N은 vocab 크기, s는 언어 특정 파라미터일 때, 다음과 같은 식으로 빈도가 주어진다.

이를 간단히 생각하면, 빈도수는 k^s에 비례한다고 볼 수 있다.
당연히.. 상위 단어(the, of)가 전체 등장 횟수의 대부분을 차지한다.
그래서 의미를 구별하는 단어는 중간 빈도 영역에 분포한다고 생각하면 된다.
여기서 우리가 얻어야 할 것은, 상위 빈도 단어는 의미가 없는 경우가 많기에 제거하면 되고,
너무 드물게 등장하는 하위 빈도 단어도 정보가 부족하기에 제외하면 된다.
그러므로 중간 단어만 쓴다고 생각하면 된다.
그럼 그 기준은 어떻게 되냐 하면은, upper cut-off와 lower cut-off는 threshold로, tuning parameter이다.

Normalization
그럼 이제 단어 빈도수를 가지고 어떤 단어를 다룰지 채택했다면,
여기서도 '정규화'가 필요하다.
예를 들어 같은 의미를 갖는 다양한 표현을 표준 형태로 바꾸는 것이다.
ex) U.S.A->USA, St.Louis->Saint Louis
이에 대한 방법은, 규칙에 맞춰 점 또는 하이픈을 제거하고 소문자로 변환한다.
그리고 dictionary에 기반해 동의어 집합으로 변환한다.
ex) car->automobile, vehicle
Stemming
다음으로 어근을 추출한다.
어형 변화를 제거하는 것이다. 이럼 어휘의 격차를 해소할 수 있다.
ex) ladies->lady, referring->refer
이에 대한 방법은, 알고리즘을 사용하는 것인데,
Porter Stemmer : 모음-자음 패턴 기반
Krovetz Stemmer : 형태적 규칙 적용
이는 약간의 문제점이 있는데, 의미 손실 가능성이 있다는 것이다.
ex) lay->lie (거짓말/눕다 ??)
Stopwords
이는 문서 분석에 유용하지 않은 단어를 제거하는 것으로, I, me, my 등의 단어가 예시이다.
모든 단어가 정보를 주는 것이 아니기 때문에, vocab size를 줄이려 의미 없는 단어를 제거한다.
이는 보편적인 정의는 없다.
근데 이걸 하면 문제점이, 문장의 의미가 깨진다는 것이다.
ex) this is not a good option -> option , to be or not to be -> null
그럼 이 VSM을 단계별로 정리해보자면,
1. Tokenization : 단어 단위 분리
2. Stemming/normalization
3. N-gram Construction : 단어쌍 생성
4. Stopword/controlled vocabulary filtering : 불필요 단어 제거 (위에서 본 stopwords의 문제점 때문에, 꼭 3번 후 4번을 진행해야 한다.)
가중치를 어떻게 할당하느냐도 중요하다.
왜냐면,
말뭉치 측면에서, 일부 용어는 문서 내용에 대한 자세한 정보를 담고 있고,
문서 측면에서, 모든 용어가 똑같이 중요한 것은 아니기 때문이다.
그럼 어떻게 할당하느냐?
두 기본 휴리스틱을 사용한다.
TF : 특정 단어의 문서 내 빈도
IDF : 특정 단어가 전체 문서에서 얼마나 드문지
-> TF-IDF 결합하여 특정 단어의 중요도 나타냄
TF(Term frequency)
이건 단순 빈도를 사용하는 방식이다.
문서에서 빈번하게 쓰인다면 그 단어는 더 중요하다는 아이디어에서 착안되었다.
c(t, d)를 d문서에서 t term이 쓰인 빈도수라 하자.
그럼 Raw TF는 tf(t, d)=c(t, d)가 된다.
근데 여기서 문제점은, 문서의 길이에 따라 빈도 차이가 당연히 난다는 것이다.
왜냐면 긴 문서에는 당연히 어쩔 수없이 빈도가 늘어나기 때문!
그래서 이것도 정규화를 해줘야 한다.
문서 길이에 따라서 단어 빈도를 보정하는 것이다.
일반적으로 긴 문서에는 불이익을 준다. (과도하진 않게!)
일단, '반복적 사전'은 '첫 사건'보다 덜 유익하다.
즉, 의미적 정보는 빈도에 비례하지 않는다는 것이다.
Maximum TF scaling

이렇게 구하는 건데, 최대 빈도를 통해 정규화하는 것이다.
Sub-linear TF scaling

요런 스케일링도 있다.
따라서 TF만으로는 먼가.. 단어의 빈도를 따지기가 애매하기 때문에,
IDF를 생각해볼 수 있다.
IDF(Inverse Document frequency)
약간 TF의 패널티항이라고 생각하면 좋다. L2 penalty 마냥!
이건 드문 빈도의 단어에 대해 더 높은 가중치를 할당한다.

IDF는 이렇게 나타낼 수 있다.
Total term frequency
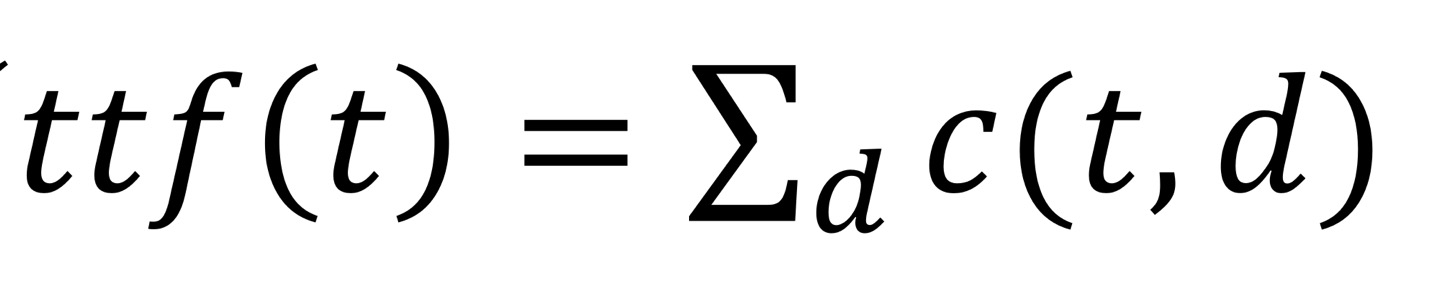
그럼 이렇게 전체 단어를 구할 수 있고, 그것과 df를 비교하는 것이다.
근데 이렇게 하면 문서 subset에서 자주 발생하는 단어를 인식할 수가 없다.
TF-IDF
위의 TF와 IDF를 결합하여 가중치를 매기는 것을 말한다.
문서에서 자주 나오면 tf는 올라갈 것이기에 가중치가 높아지고,
전체 문서에서 드물게 나타날수록 idf가 올라가서 가중치가 높아진다.
Word2vec(Local contexts)
이건 중심 단어에서 몇 위치 떨어진 단어를 사용하는데, 중심단어/맥락단어 쌍을 'skip-gram'이라고 한다.
예를 들어 중심단어를 하나 정하면, 그 주변 몇 개의 단어를 맥락단어로 본다.
그리고 Word2vec은 모든 단어를 중심단어/맥락단어로 고려한다. 보통 3-5개의 단어 위치를 고려한다.
skip-gram에서는, 문맥단어는 2의 배수 개수로 정해져있다. 양쪽을 보기 때문!
이 skip-gram objective function은 중심단어와 주변단어간의 조건부 확률을 최대화하는 목적함수를 가진다.
각 위치에 대해, 주어진 중심 단어 wt에 대한 문맥 사이즈 m 내의 문맥 단어를 예측하는 것:
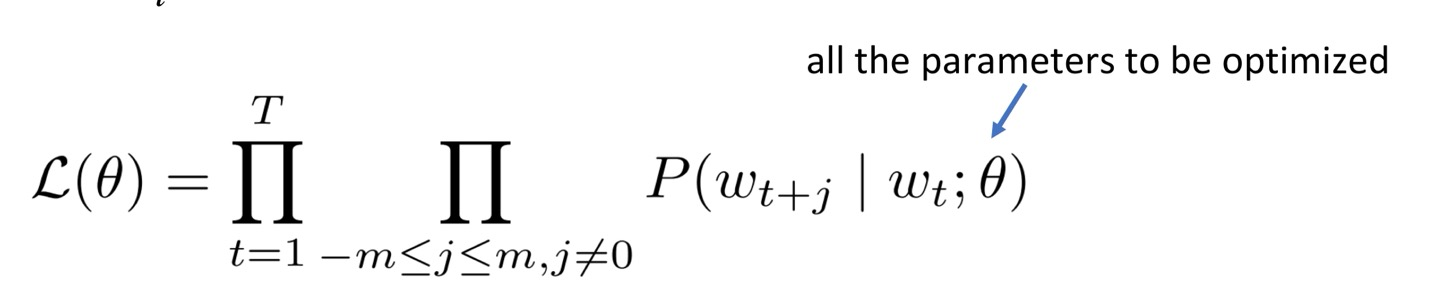
으악 너무 어려워서 패스
3page는 다음에..
'AI > 데이터과학' 카테고리의 다른 글
| Page Ranks and Random Walks in Graph (3rd page 계산 추가) (2) | 2024.12.14 |
|---|---|
| NN(Neural Networks), Convolution, Pooling (0) | 2024.12.14 |
| 결정트리(Decision Tree) (1) | 2024.12.12 |
| 회귀/분류 (1) | 2024.12.10 |
| 분류(K-Means, Agglomerative Clustering, DBSCAN) (4) | 2024.10.21 |