
"회귀"란?
지도학습 중 하나로, 입력과 출력이 주어지면 이를 바탕으로 수치값을 예측하는 모델을 만들어내는 것이다.
예를 들어, 아래와 같은 데이터가 주어졌다면 x값이 7일 때 y값은 어떤 수에 가장 근사할까?
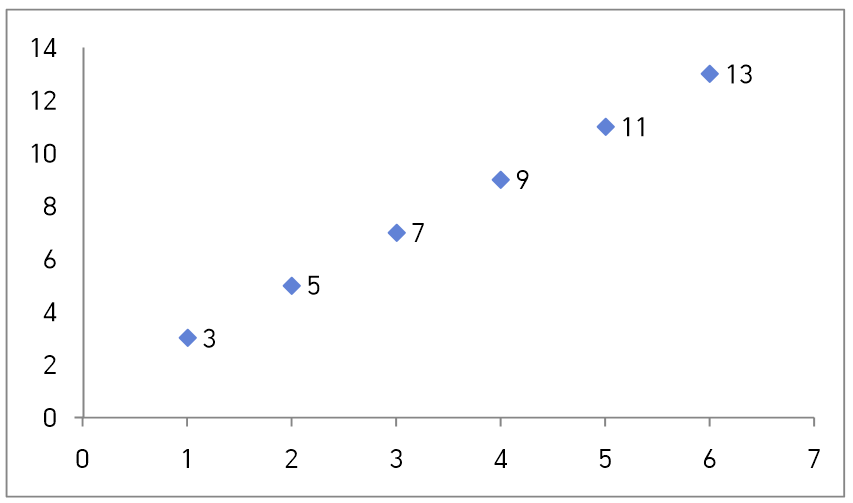
내 생각에는 아무래도 y는 15가 될 것 같다. 물론 아닐 수도 있지만 말이다.
이처럼 x와 y가 주어졌을 때 이 데이터를 가장 잘 나타내는 선을 찾는 것이 회귀라고 할 수 있다.
여기서 입력인 x는 독립변수, Input, feature라고 불리기도 하고,
출력인 y는 종속변수, Output, Response라고 불리기도 한다.
그럼 이 회귀식은 어떻게 표현할 수 있느냐 하면, 우선 파라미터들이 필요하다.
가장 단순한 선형회귀식을 생각해보자.
위의 그래프의 데이터들로 회귀식을 만들어본다면,
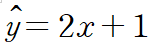
이렇게 나타내는 것이 가장 적당할 것이다.
여기서 y위에 모자같은 기호가 있는데, 이는 hat이라고 불리며, 예측값에 쓰인다.
따라서 이 식은, x를 넣으면 2를 곱하고 1을 더한 값이 y가 될 것이라고 예측하는 식이 되는 것이다.
이 단순 회귀식을 보면, x와 곱해진 수가 있고, 변수가 곱해지지 않고 더해진 수가 있다.
x와 곱해진 2는 이 식의 기울기, slope이고, 혼자 더해진 1은 상수항 intercept이다.
회귀식을 찾을 때 우리가 가장 신경써야 하는 것들은 이 slope와 intercept이다.
가장 적절한 slope과 intercept를 찾아야 하는데, 이것들을 parameter라고 한다.
parameter를 우선 적당한 값으로 초기화하고, 알맞은 값이 되도록 update시켜주면서 회귀식을 찾는 것이다.
가장 적절한 파라미터가 되면 파라미터 변수 위에 hat을 붙여 표기하게 된다.
이제 회귀식의 구성은 알겠는데, 그럼 이 회귀식은 어떻게 찾는지가 궁금할 것이다.
여기서 잠깐 빠르게 모델링 과정을 알아보겠다.
모델링 과정
1. 어떤 모델이 이 데이터를 잘 나타낼지 모델을 고르고,
2. 예측값과 실제값 사이 손실을 나타내는 손실함수를 어떤 것을 사용할지 선택한 후,
3. 모델을 적합시켜 가장 적절한 파라미터를 찾아 모델을 만든 다음
4. 모델의 성능을 평가하는 것이다.
회귀 모델링
첫 번째, 모델을 고르겠다.
여기서는 우선 회귀 모형 중에서도 단순 선형 회귀 모델을 고를 것이다.
그럼 아까와 같이 slope과 intercept, x, y_hat으로 이루어진 회귀식을 세울 수 있을 것이다. (종종 intercept를 제외하고 식을 세우기도 한다)
여기서 알아둬야 할 것은, x와 y사이 관계는 대부분 비선형 관계라는 것이다.
자연현상에서 관측값이 항상 일정할 순 없고, 기계 작동에서의 회귀식이더라도 오차/오류가 발생할 수 있기 때문이다.
그래서 아무리 최대한 적절한 선형식으로 표현되더라도 y에는 hat이 붙는 것이다.
두 번째, 손실함수를 정한다.
이 손실함수는 우리의 예측이 좋은지 나쁜지 평가해주는 방법이다.
예측값과 실제값 사이 차이를 보는 것이고, 예측값이 실제값과 비슷할 수록 손실함수 값이 0에 가깝다.
손실함수의 종류도 여러가지가 있는데, 이를 정하는 조건은 아래를 참고할 수 있습니다.
양적(quantitative)자료인지 질적(qualitative)자료인지, 이상치를 고려했는지, 어떤 에러든 동등한지(예를 들어, 암인데 암이 아니라고 판정하는 오류와 암이 아닌데 암이라고 판정하는 오류가 동등한가? 암인데 암이 아니라고 판정하는 오류가 더 위험하다.)
이를 따지면서 손실함수(Loss Function)를 정하게 된다.
예를 들어, L1 loss는 예측값과 실제값의 차이의 절댓값으로 나타내고,
L2 loss는 예측값과 실제값의 차이의 제곱으로 나타낸다.
L1 loss는 모두 더하면 0에 가까워질 것이고, L2 loss는 모든 오차를 제곱해서 더하면 이상치의 영향을 많이 받을 것이다.
그리고 당연히! 이 손실함수는 어떤 한 점에만 적용시켜서 보는 것이 아니라, 모든 데이터셋에 적용시켜서 그 오차를 확인해야 한다.
그리고 이 데이터 샘플에 대한 평균 오차는 이 모델이 샘플에 얼마나 알맞는지를 나타낸다. 모집단에 대해서가 아니라!
위에서 말했던 L1 loss를 모두 더해서 데이터 수인 n으로 나눈 값은 MAE라고 하고,
L2 loss를 모두 더해서 n으로 나눈 값을 MSE라고 한다.
세 번째, 모델을 적합시킨다.
모델을 적합시킨다는 말이 생소하게 들릴 텐데, 영어로 하면 fit, 즉 모델을 데이터에 맞춘다는 뜻으로 생각하면 된다.
두 번째 단계에서 만든 손실함수를 최소화하는 것이 좋은 모델이다.
손실함수를 최소화하려면 어떻게 해야할까?
우선 MSE 기준으로 생각해보겠다. MSE는 파라미터 두 개로 나타내진 이차식일 것이다. 그리고 제곱합이므로 무조건 양수이다.
고등학교 때 한 번쯤 배웠을 텐데, 양수 이차식, 즉 아래로 볼록한 함수의 최솟값을 찾으려면 미분값이 0인 지점을 찾아야 했다.
여기선 파라미터 두 개로 나타내진 이차식이므로, 각 파라미터를 편미분해서 0이 되는 지점을 찾으면 된다.
네 번째, 모델을 평가한다.
이제 마지막 단계이다. 이 단계에서는 평균, 분산, 상관계수 등을 이용한다.
대부분 MSE에 루트를 씌운 RMSE를 이용한다. 이는 y와 단위가 같다. RMSE가 작을 수록 정확한 예측이다.
아니면 잔차에 대한 plot을 그려 예측값과 실제값이 얼마나 차이나는지 알아볼 수 있다.
'통계 > 회귀' 카테고리의 다른 글
| 회귀모형의 선택 (19) | 2024.11.14 |
|---|---|
| 중선형회귀모형 - 자료에 대한 진단 (6) | 2024.11.07 |