
기계학습은 지도학습/비지도학습/강화학습으로 나뉜다.
강화학습이란?
에이전트가 환경과 상호작용하며 보상을 최대화하는 행동전략을 학습하는 방법론.
기계학습+최적화 -> 에이전트가 목표 달성 위해 스스로 학습
정답으로부터 학습하는 게 아니라, 보상을 통해 학습함.
즉각적인 응답이 오지 않는 경우도 많다. 피드백이 때때로 지연돼서 부여.
시간 혹은 순서가 중요.
에이전트의 행동이 이후 환경으로부터 받게 될 데이터에 영향 미칠 수 있음.
<예시>
- 헬리콥터의 스턴트 비행
- 체스, 바둑 등 보드게임
- 투자 포트폴리오 관리
- 휴머노이드 로봇의 보행
RL(강화학습)의 요소
1. 보상
숫자로 주어지는 피드백 신호. t시점의 보상은 Rt
"에이전트가 t 시점에 얼마나 잘하고 있는지"
그냥 t시점 바로 다음의 보상을 의미함.
--> 누적 보상 최대화가 목표!
2. 에이전트&환경
관측, 행동, 보상
[ 각 시점 t에서의 ~ ]
Agent
- 특정 행동 At 수행
- 환경으로부터 관측된 환경 Ot 받음
- 스칼라 보상인 Rt 받음
Environment
- 특정 행동 At 받음
- 새로운 환경 O(t+1)방출
- 새로운 보상 R(t+1)방출
3. 상태
에이전트가 특정 시점의 환경에 대해 가지는 정보.
환경의 현재 상황을 나타냄.
ex) 게임에서 말의 위치와 종류
환경 상태와 에이전트 상태로 나뉨.
강화학습 에이전트는 에이전트 상태를 바탕으로 다음 행동 선택
- 에이전트 상태 : 에이전트가 환경과 상호작용한 History를 기반으로 정의
- 환경 상태 : 에이전트는 환경상태의 모든 정보를 알 수도 있지만, 일부만 관측할 수도 있음.
4. 정책
에이전트의 행동에 대한, 행동을 결정하는 함수
x라는 상황에서 agent가 어떻게 행동할 건지?
상태로부터 행동으로의 맵핑
결정론적 정책 / 확률론적 정책
5. 가치
가치 : 현재 상태 혹은 현재 상태에서 이런 행동이 얼마나 좋은지
가치함수 : 미래 보상에 대한 예측, 특정 상태가 좋은지 안좋은지 판단 위해 사용.
전체 장기적인 결과에서, 현재 이 행동이 얼마나 좋은지
가치 함수는 여러 행동 중 선택하기 위해서도 활용됨.
감마는 할인율/감쇄율을 나타내며, 미래 보상에 대한 현재 가치를 계산할 때 사용됨. 즉각적 보상과 비교했을 때 미래의 보상에 얼마나 가치를 두는가에 따라 결정
6. 모델
환경이 어떻게 작동하는지에 대한 에이전트의 표현
환경이 다음에 뭘 할지를 예측.
P는 다음 상태 예측, R은 다음 즉각적인 보상 예측
순차적 의사결정
- 목표 : 미래 보상을 최대화하는 행동 선택
- 행동은 즉각적 보상을 가져다주지 않을 때도 있고, 오랜 시간 후 결과가 나오기도 한다.
- 현재의 보상을 일부 희생하더라도 긴 시간 뒤의 보상이 더 나을 수도.
Exploration (탐험/탐색) : 환경에 대해 좀 더 많은 정보를 얻어야 함. ex)새로운 식당 도전
Exploitation (활용) : 주어진 정보를 바탕으로 보상을 최대화해야 함. ex)전에 가본 맛있는 식당 선택
시행착오 학습 : 누적보상 최대화, 미지의 환경에 대한 정보/경험 획득 후 활용, 새로운 곳 탐색에 있어 보상 너무 잃지 않도록
미지의 세계에서, 우연히 reward를 찾게 되면, 이후 행동은 이런 reward를 찾도록 반복하는 탐험/탐색 과정이 일어나는데, 기존의 정보만 '활용' 한다면 전역최적해에 해당하는 공간까지 못감.
epsilon-greedy
특정 상태에서, epsilon은 [0.0, 1.0] 범위 안에 있음. 탐색 초기에는 이 엡실론값이 크도록 설계(Exploration)하지만, 각 에피소드 이후에 epsilon decay값을 곱해서 epsilon을 줄이게 된다. 그치만 최소값 이하로는 줄이진 않음.
Maze-Example
보상 : 한 번 움직일 때마다 -1
행동 : 양옆위아래
상태 : Agent의 위치
이 예시에서는, Policy만 있어도 강화학습이 가능하다는 것을 알 수 있다.
이 미로에 대한 방향을 나타낼 수도 있지만, 그 목표까지 가는 경로의 value를 나타내는 value function을 사용할 수도 있다.
에이전트는 환경에 대한 내부 모델을 갖고 있을 수 잇고,
P는 특정 행동이 어떻게 상태를 변화시키는지 예측하고,
R은 각 상태에서 얼마나 보상이 주어지는지 예측한다.
RL Agents
1. 가치기반
정책 없고, 가치함수만
2. 정책기반
가치함수 없고, 정책만
3. 액터 크리틱
정책과 가치함수 둘 다
4. 모델프리
정책 and/or 가치함수, 모델이 없음
5. 모델기반
정책 and/or 가치함수, 모델있음
RL Agent 분류 다이어그램
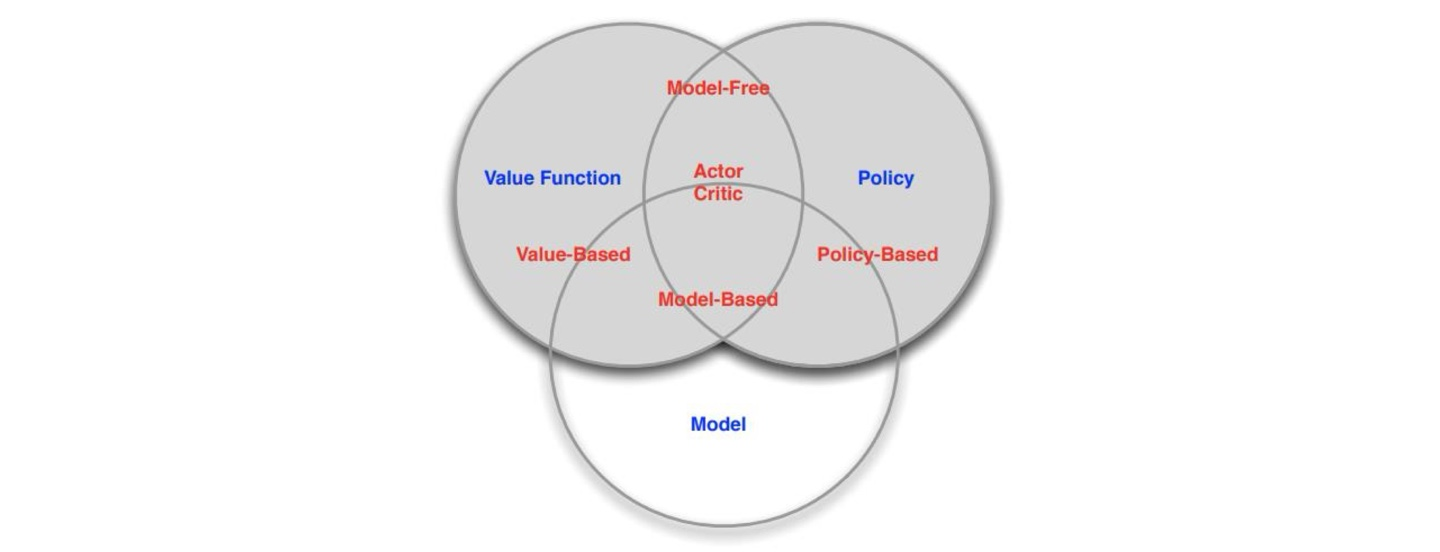
학습과 계획
순차적 의사결정에서 두가지 근본적 문제
- 강화학습 : 환경이 초기에는 미지상태임, 에이전트가 환경과 상호작용하여 정책 개선
- 계획 : 환경의 모델이 알려져 있고, 에이전트가 모델 사용해 계산 수행(외부와의 상호작용 없음)하여 정책 개선함.
Atari Example : 강화학습
게임 규칙 미지, 게임 플레이해서 interactive하게 학습
Atari Example : 계획
게임 규칙 알려짐, 에뮬레이터에게 다음 상태 질의 가능 (상태 s에서 행동 a를 수행하면~ 다음 상태가 어떤 상태일지, 다음 점수가 몇 점일지) - Tree탐색과 같은 방법으로 최적 정책 탐색/계획
Q-learning
Q-table 혹은 Q-function을 이용해 특정 상태에서 특정 행동을 할 경우의 가치의 추정된 값을 저장함(상태-가치 함수)
특정한 상태-가치 쌍(s, a)에 대해 Q-value는 해당 상태 s에서 행동 a를 택하고, 그 이후 Q-function의 최적 선택을 지속했을 때의 기대 누적 보상을 나타낸다.
목적 : Q-table 만들기.
Q-table은?
상태의 수와 행동의 수에 크기 비례.
<예시>
- 격자 문제 (파란색 닿으면 +1, 빨강 닿으면 -1, 이동하면 -0.01)
- 제한된 시야 상태에서 전체 부분에 퍼져있는 세 개의 공을 찾는 문제
시간차 학습
보상을 나타낼 때,
현재 받을 수 있는 즉각적인 보상 + 앞으로 받을 수 있는 보상으로 나타내는데,
앞으로 받을 수 있는 보상은 즉각적인 건 아니니깐.. 그 가중치를 조금 줄여줌.
DQN (Deep Q-Network)
Q-learning with DNN
Q-table대신, 상태-행동 가치 함수를 위해 Deep Q-network를 학습한다.
입력으로 연속된 화면들을 사용한다.
'AI > 인공지능' 카테고리의 다른 글
| 최적화, Optimization (0) | 2024.06.12 |
|---|---|
| VAE, Diffusion (vision transformer 추가하가( (3) | 2024.06.11 |
| LLM (0) | 2024.06.10 |
| GAN (2) | 2024.06.09 |
기계학습은 지도학습/비지도학습/강화학습으로 나뉜다.
강화학습이란?
에이전트가 환경과 상호작용하며 보상을 최대화하는 행동전략을 학습하는 방법론.
기계학습+최적화 -> 에이전트가 목표 달성 위해 스스로 학습
정답으로부터 학습하는 게 아니라, 보상을 통해 학습함.
즉각적인 응답이 오지 않는 경우도 많다. 피드백이 때때로 지연돼서 부여.
시간 혹은 순서가 중요.
에이전트의 행동이 이후 환경으로부터 받게 될 데이터에 영향 미칠 수 있음.
<예시>
- 헬리콥터의 스턴트 비행
- 체스, 바둑 등 보드게임
- 투자 포트폴리오 관리
- 휴머노이드 로봇의 보행
RL(강화학습)의 요소
1. 보상
숫자로 주어지는 피드백 신호. t시점의 보상은 Rt
"에이전트가 t 시점에 얼마나 잘하고 있는지"
그냥 t시점 바로 다음의 보상을 의미함.
--> 누적 보상 최대화가 목표!
2. 에이전트&환경
관측, 행동, 보상
[ 각 시점 t에서의 ~ ]
Agent
- 특정 행동 At 수행
- 환경으로부터 관측된 환경 Ot 받음
- 스칼라 보상인 Rt 받음
Environment
- 특정 행동 At 받음
- 새로운 환경 O(t+1)방출
- 새로운 보상 R(t+1)방출
3. 상태
에이전트가 특정 시점의 환경에 대해 가지는 정보.
환경의 현재 상황을 나타냄.
ex) 게임에서 말의 위치와 종류
환경 상태와 에이전트 상태로 나뉨.
강화학습 에이전트는 에이전트 상태를 바탕으로 다음 행동 선택
- 에이전트 상태 : 에이전트가 환경과 상호작용한 History를 기반으로 정의
- 환경 상태 : 에이전트는 환경상태의 모든 정보를 알 수도 있지만, 일부만 관측할 수도 있음.
4. 정책
에이전트의 행동에 대한, 행동을 결정하는 함수
x라는 상황에서 agent가 어떻게 행동할 건지?
상태로부터 행동으로의 맵핑
결정론적 정책 / 확률론적 정책
5. 가치
가치 : 현재 상태 혹은 현재 상태에서 이런 행동이 얼마나 좋은지
가치함수 : 미래 보상에 대한 예측, 특정 상태가 좋은지 안좋은지 판단 위해 사용.
전체 장기적인 결과에서, 현재 이 행동이 얼마나 좋은지
가치 함수는 여러 행동 중 선택하기 위해서도 활용됨.
감마는 할인율/감쇄율을 나타내며, 미래 보상에 대한 현재 가치를 계산할 때 사용됨. 즉각적 보상과 비교했을 때 미래의 보상에 얼마나 가치를 두는가에 따라 결정
6. 모델
환경이 어떻게 작동하는지에 대한 에이전트의 표현
환경이 다음에 뭘 할지를 예측.
P는 다음 상태 예측, R은 다음 즉각적인 보상 예측
순차적 의사결정
- 목표 : 미래 보상을 최대화하는 행동 선택
- 행동은 즉각적 보상을 가져다주지 않을 때도 있고, 오랜 시간 후 결과가 나오기도 한다.
- 현재의 보상을 일부 희생하더라도 긴 시간 뒤의 보상이 더 나을 수도.
Exploration (탐험/탐색) : 환경에 대해 좀 더 많은 정보를 얻어야 함. ex)새로운 식당 도전
Exploitation (활용) : 주어진 정보를 바탕으로 보상을 최대화해야 함. ex)전에 가본 맛있는 식당 선택
시행착오 학습 : 누적보상 최대화, 미지의 환경에 대한 정보/경험 획득 후 활용, 새로운 곳 탐색에 있어 보상 너무 잃지 않도록
미지의 세계에서, 우연히 reward를 찾게 되면, 이후 행동은 이런 reward를 찾도록 반복하는 탐험/탐색 과정이 일어나는데, 기존의 정보만 '활용' 한다면 전역최적해에 해당하는 공간까지 못감.
epsilon-greedy
특정 상태에서, epsilon은 [0.0, 1.0] 범위 안에 있음. 탐색 초기에는 이 엡실론값이 크도록 설계(Exploration)하지만, 각 에피소드 이후에 epsilon decay값을 곱해서 epsilon을 줄이게 된다. 그치만 최소값 이하로는 줄이진 않음.
Maze-Example
보상 : 한 번 움직일 때마다 -1
행동 : 양옆위아래
상태 : Agent의 위치
이 예시에서는, Policy만 있어도 강화학습이 가능하다는 것을 알 수 있다.
이 미로에 대한 방향을 나타낼 수도 있지만, 그 목표까지 가는 경로의 value를 나타내는 value function을 사용할 수도 있다.
에이전트는 환경에 대한 내부 모델을 갖고 있을 수 잇고,
P는 특정 행동이 어떻게 상태를 변화시키는지 예측하고,
R은 각 상태에서 얼마나 보상이 주어지는지 예측한다.
RL Agents
1. 가치기반
정책 없고, 가치함수만
2. 정책기반
가치함수 없고, 정책만
3. 액터 크리틱
정책과 가치함수 둘 다
4. 모델프리
정책 and/or 가치함수, 모델이 없음
5. 모델기반
정책 and/or 가치함수, 모델있음
RL Agent 분류 다이어그램
학습과 계획
순차적 의사결정에서 두가지 근본적 문제
- 강화학습 : 환경이 초기에는 미지상태임, 에이전트가 환경과 상호작용하여 정책 개선
- 계획 : 환경의 모델이 알려져 있고, 에이전트가 모델 사용해 계산 수행(외부와의 상호작용 없음)하여 정책 개선함.
Atari Example : 강화학습
게임 규칙 미지, 게임 플레이해서 interactive하게 학습
Atari Example : 계획
게임 규칙 알려짐, 에뮬레이터에게 다음 상태 질의 가능 (상태 s에서 행동 a를 수행하면~ 다음 상태가 어떤 상태일지, 다음 점수가 몇 점일지) - Tree탐색과 같은 방법으로 최적 정책 탐색/계획
Q-learning
Q-table 혹은 Q-function을 이용해 특정 상태에서 특정 행동을 할 경우의 가치의 추정된 값을 저장함(상태-가치 함수)
특정한 상태-가치 쌍(s, a)에 대해 Q-value는 해당 상태 s에서 행동 a를 택하고, 그 이후 Q-function의 최적 선택을 지속했을 때의 기대 누적 보상을 나타낸다.
목적 : Q-table 만들기.
Q-table은?
상태의 수와 행동의 수에 크기 비례.
<예시>
- 격자 문제 (파란색 닿으면 +1, 빨강 닿으면 -1, 이동하면 -0.01)
- 제한된 시야 상태에서 전체 부분에 퍼져있는 세 개의 공을 찾는 문제
시간차 학습
보상을 나타낼 때,
현재 받을 수 있는 즉각적인 보상 + 앞으로 받을 수 있는 보상으로 나타내는데,
앞으로 받을 수 있는 보상은 즉각적인 건 아니니깐.. 그 가중치를 조금 줄여줌.
DQN (Deep Q-Network)
Q-learning with DNN
Q-table대신, 상태-행동 가치 함수를 위해 Deep Q-network를 학습한다.
입력으로 연속된 화면들을 사용한다.
'AI > 인공지능' 카테고리의 다른 글
| 최적화, Optimization (0) | 2024.06.12 |
|---|---|
| VAE, Diffusion (vision transformer 추가하가( (3) | 2024.06.11 |
| LLM (0) | 2024.06.10 |
| GAN (2) | 2024.06.09 |