
Sequence-to-sequence 모델을 간단히 말하자면,
기계 번역을 위한 sequence-to-sequence 모델
입력 -> 인코더 -> 문맥 벡터(context vector) -> 디코더 -> 출력
Auto Encoder (AE) 란?
Input~Code전까지 : Encoder - 입력의 중요한 특성을 추출/차원축소
Code - 잠재 벡터(Latent Vector), 병목현상
Code후~Output까지 : Decoder - 데이터 확장 / 재구
- 신경망의 일종. 차원 축소나 특성 학습에 활용
- 입력 데이터를 받아 압축된 표현 생성
- 다시 원본 데이터로 재구성하되, 이 과정에서 데이터의 특성이 유지되는 것을 목표로 함.
- 비지도 학습 ( label 없는 data, 입력 그대로 복원 want )
- 학습 목표 : 입력 data vs 재구성 data 차이 min
- data의 핵심 특징 포착하는 유용한 압축 표현 학습 가능
- 데이터의 중요한 특징 보존 / 불필요한 정보 제거
- 차원 축소 / 데이터 전처리 / 데이터 압축 / 노이즈 제거 등 다양 분야 활용
그럼 이 Seq2Seq 이랑 AE는..
입력 받아서 인코더에 넣고, 벡터로 만들어서, 디코더에 넣고, 출력 생성하면,
같은 거 아닌가..? 싶을 수도 있는데,
차이점이 큼.
Seq2Seq vs AE 차이점!
Seq2Seq는 시퀀스 데이터를 받아서, 새로운 다른 시퀀스로 변환하고 싶은 지도학습 모델임.
즉, Seq2Seq의 문맥 벡터는, input의 내용을 요약한 벡터이다.
또, 이 문맥벡터에서 attention score를 계산하면서 다르게 표현해서 시간적 의존성 학습.
AE는 어떠한 입력을 받아서, 압축했다가 풀면서 입력과 동일한 내용의 데이터를 재구성하고 싶은 비지도학습 모델임.
AE의 Latent 벡터는, input을 압축하면서 input의 이상치 부분을 제거하는 방향으로 학습하며 더 좋게 표현하게 됨.
출처 - 낭만 님 블로그(tstory)
MLP (Multi Layer Perceptron)
입력층 - 은닉층(여러 층) - 출력층
AE 활용법
1. 영상 압축
Latent vector의 차원 : 정보의 압축 정도. 너무 높은 latent vector 차원은 overfitting 될 위험 있음.
Denoising AE : original input -> Noise 추가한 Noisy Input -> Encoder -> latent vector -> Decoder -> Denoised Image
==> 결과물과 original Image의 차이를 MSE 등으로 비교해서 학습
==> 사진의 일부를 masking 해놓고 AE를 학습시키면 다시 복원 가능
Inpainting with AE
- 어떠한 마스킹된 사진을 봤을 때, 인간은 그 공간을 머릿속에서 채워넣을 수 있음.
- 왜냐? 이미지는 다양하겠지만.. 사물은 어느정도 구조화되어있고, 사람이 이걸 이해하고 있기 때문,
- AE도 이걸 이해해서 마스킹된 사진을 복구 가능
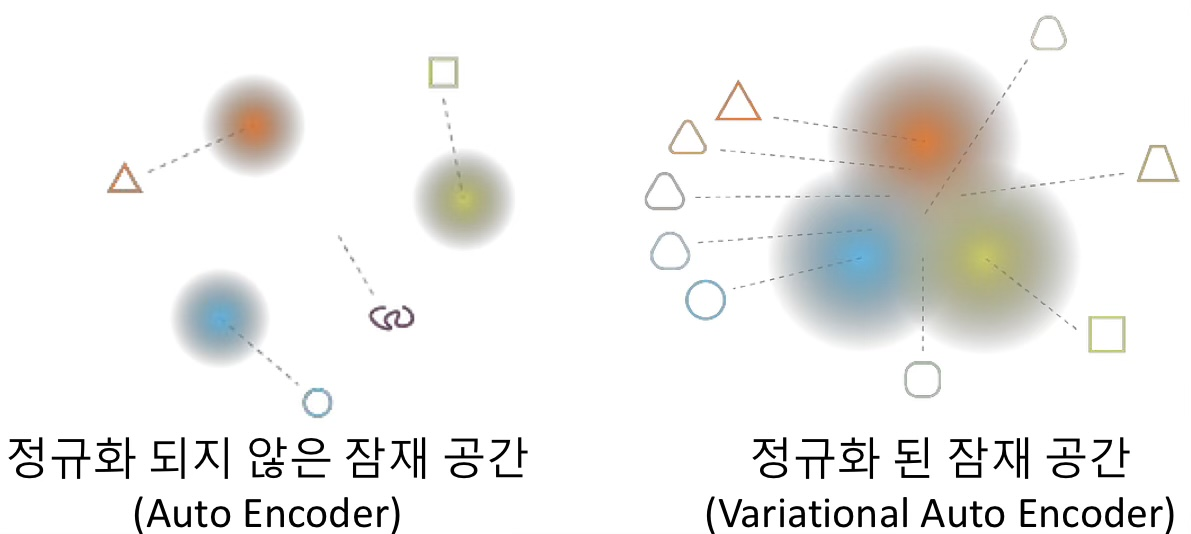
VAE (Variational Auto Encoder) 란?
Encoder로 차원 축소 후, 이를 Mean vector 와 Standard deviation vector로 출력을 만들고, 이 둘을 합쳐 Sampled Latent vector를 만들어 Decoder에 넣는다.
인코더의 출력을 단일 잠재 벡터가 아닌 평균과 분산 값으로 하는 확률 분포로 취급해서, 확률적으로 잠재 벡터를 추출함.
정규화 제약으로 인해 잠재 분포가 가우시안에 가까워지도록 유도함.
AE vs VAE
공통점 : 데이터를 저차원 벡터로 인코딩하고, 이를 다시 복원하는 것이 목표.
차이점 : 활용!
AE - 데이터 압축, 특징 추출, 차원 감소
VAE - 확률적 생성 모델. 새로운 데이터 샘플 생성 가능.
Vision Transformer
Contrastive Learning / CLIP(Contrastive Language-Image pre-training)
자기 지도 학습의 일종으로, 데이터 간 유사성을 max/minimize 하도록 모델 학습
유사 샘플 : 가깝게, 비유사 샘플 : 멀게
정말 많은 영상-텍스트 쌍을 활용해 Contrastive 학습을 하고,
글에서 추출한 임베딩과 영상에서 추출한 임베딩 사이의 연관성을 학습
-> 글과 영상이 원래의 쌍이었다면 Positive, 아니라면 Negative로 샘플링하기.
모델의 입력은 글과 영상이고, 출력은 쌍인지 아닌지 여부이다. (Zero-shot learning capability)
Diffusion
원본 데이터에 점진적으로 노이즈 추가하는 forward diffusion process
순수 노이즈로부터 원본 데이터로의 과정인 reverse denoising process (위와 반대)
reverse denoising process에 대해 학습
Text-conditioned diffusion
Diffusion 과정에서 Text embedding을 참고해 diffusion을 수행하도록 학습
-> 이후 Pure random noise로부터 text embedding 을 참고해서 diffusion denoising
StableDiffusion
Text-to-image 생성을 위한 Diffusion모델
코드와 모델이 공개되어 있음. 일반 GPU환경에서 작동 가능
MidJourney
Text-to-image를 위한 Diffusion모델
Discord를 이용한 생성기능 제공
유료 서비스
DALL-E
OpenAI사의 Text-to-image모델
GPT-3 기반, image-text pair로 학습
Language model처럼 이전의 입력 기반으로 auto regressive 방법으로 다음 token 예측/생성
CLIP으로 여러 출력에 대해 순위 매김
DALL-E 2
VAE대신 Diffusion으로 영상 생성
DALL-E보다 4배 더 큰 해상도의 영상 생성 가능
더 큰 영상을 더 빠른 속도로 생성
Outpainting / in-painting 기능 추가
출처 - 충남대 박지훈 교수님 수업자료