
본 게시글은 충남대 정상근 교수님의 강의자료를 바탕으로 작성한 글입니다.
N2M이란?
N-to-M 문제로, N개의 입력을 받아 M개의 출력을 생성하는 자연어 처리 문제 유형이다.
이 글에서 다뤄볼 것은 아래와 같다.
1. N2M 문제 정의 및 이해
2. Encoder-Decoder vs Decoder-only 모델 구조 차이
3. Decoder 출력에서 Search Strategy를 통한 문장 생성 원리 이해
4. Text Summarization을 위한 모델 구조와 Loss Function 이해
N2M 문제 정의 및 이해
위에서 말했듯 N개의 input Token으로부터 M개의 output token을 생성하는(구하는) 문제이다.
자연어 처리 전반에서 흔한 구조다. 번역, 요약, 질문 응답 등..
Text Summarization
1. Extractive Summarization
원문에서 중요한 문장/구를 그대로 발췌하는 것
2. Abstractive Summarization
내용을 새로운 표현으로 재작성하는 것. 이건 생성 기반!
Rule Based Method
이건 1. Extractive 방식이다.
문법 규칙, 구문 구조 분석 등을 활용해 문장을 선택한다.
문법적으로 핵심이 되는 문장을 추출해내면 되는 것인데, 구현은 쉽지만 표현의 다양성이 부족하고 복잡한 의미 파악이 어렵다는 단점이 있다.
Model Based Summarization (Encoder-Decoder)
이건 2. Abstractive 방식이다.
1) Encoder->Decoder 구조 모델
인코더에서는 문서의 의미를 벡터로 인코딩하고, 디코더에서는 요약문을 생성한다.
2) Decoder Only 구조 모델
Decoder만으로 문장을 생성한다. 문맥을 이해하며 하나씩 단어를 생성하는 것이고, 이때 장점은 Pretrained model을 활용할 수 있다는 것이다.
3) Instruction-Tuned 모델
입력을 넣으면, 모델이 Instruction에 맞춰 Abstractive Summarization을 생성하는 것이다.
특정 목적에 맞춘 프롬프트(Instruction)을 기반으로 정교한 요약을 생성할 수 있기에 다양한 Task에 적용할 수 있다.
Summarization에서 사용하는 데이터셋은 뉴스/기사 데이터(CNN/Dailymain/XLSum), 웹 데이터(WikiLingua/SAMSum), 도서 데이터(BillSum/Pubmed-Summarization)이다.
보통 머 수백단어로 구성된 뉴스 기사를 입력, 요약은 핵심만을 담은 2~3문장으로 학습을 진행한다.
Architecture types
Seq-2-Seq Model
Encoder(RNN) : 입력 시퀀스를 벡터로 인코딩
Decoder(RNN) : 인코딩된 벡터를 기반으로 출력 시퀀스 생성
Decoder에서는 <bos> 토큰을 시작시 입력받고, 순차적으로 다음 토큰을 생성한다. 끝나는 조건 <eos> 토큰까지!
Decoder-based Trasnformer Model

Transformer의 Decoder만 사용하는 모델로, 각 입력 토큰에 대해 Posigional Embedding Layer를 통과시킨다.
이후 여러개의 Decoder Block(Masked Self-Attention->Feed Forward)을 통과하고, 결과적으로 Output Token Vector를 출력한다.
보통 GPT, BART가 Decoder-based Transformer 모델에 속한다.
Encoder-Decoder Model

Encoder Block은 Self-Attention + Feed Forward
Decoder Block은 Masked Self-Attention + Encoder-Decoder Attention + Feed Forward
일단 입력 Seq이 Encoder를 통해 인코딩되고, 이후 Decoder가 인코딩된 벡터와 기존 생성된 출력 Seq를 기반으로 다음 토큰을 생성한다.
Autoregressive vs. Non-Autoregressive
Autoregressive는 이전에 생성된 토큰들을 참고해서 순차적으로 생성하는 것으로, GPT, BART, T5모델 등이 있다.
이를 학습시킬 때에는, 정답 Seq를 오른쪽으로 1칸 Shift한 것을 Decoder에 입력으로 넣고, 다음 단어를 예측하도록 학습한다.

예를 들면, <bos> -> <bos> Economy -> <bos> Economy grows -> <bos> Economy grows due ... 이런 식으로 진행된다.
이런 방식을 사용하면 예측 결과가 누적되기 때문에, 초기 예측 오류가 후속 결과에도 영향을 준다.
Non-Auto는 모든 토큰을 동시에 병렬 생성하기에, 빠르지만 품질 저하 문제가 발생 가능하다.
Decoder Only Model
GPT 계열 모델의 기본 구조이다.
입력이 Token Embeddings + Positional Embeddings를 받아 여러 Decoder Block을 지나 Autoregressive하게 출력을 한 토큰씩 생성해낸다. 입력만으로 충분한 정보가 주어진 task(요약, 생성)에 적합하다.
이때 Text 생성 Flow는 다음과 같다.
이제까지의 input을 모두 transformer-based model에 넣고, 그 결과를 search strategy를 통해 여러 후보 중 하나를 선택한다. 그리고 그때 나온 출력을 그 다음 입력에 함께 넣는다. 그림을 보면 이해가 쉬울 것이다.
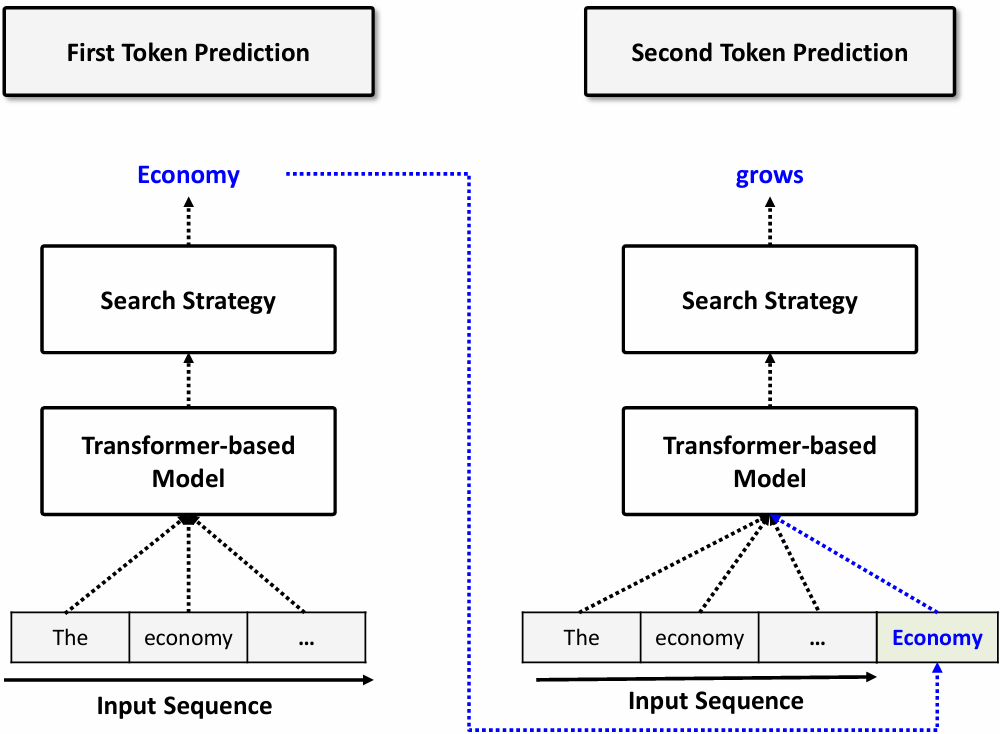
Input Preprocessing
이런 모델을 생각할 때, 항상 꼭 필요한 것은 Input이다.
근데 Input을 그냥 넣으면 안되는 경우가 많다. 보통 전처리를 해서 넣는다.
그럼 이런 N2M Model에서의 Input 전처리는 어떤 식으로 진행할까?

일단 Input text가 들어오면 이를 Tokenizer에 전달한다.
Tokenizer에서는 Token으로 분리하는 Tokenizing을 진행하고, <bos>, <eos>, <pad> 등 Special token을 추가한다. 이후 숫자 ID라고 볼 수 있는 Vocabulary ID로 변경한다. 이 결과를 Tokenizer가 Embedding Layer에 전달한다.
Embedding Layer를 통과시키며 모델이 처리할 수 있는 벡터 형식으로 변환하고, Input token vectors를 생성해낸다.
모델은 이 input token vectors를 입력으로 받는 것이다.
Output Postprocessing

그럼 모델의 출력을 후처리하는 과정도 있을 것이다.
이때는모델이 출력한 vector(Logit)을 Softmax를 통해 확률 분포로 변환 후 Search Strategy로 Sampling 또는 탐색 전략을 진행해서 토큰을 선택하게 된다.
그리고 이 결과를 Vocabulary ID로 바꾼 후, 실제 단어로 다시 변환하는 과정을 <eos> token이 등장할 때까지 반복한다.
위에 잠깐 나온 Search Strategy는 두 가지로 나뉜다.
Deterministic :
항상 동일한 출력을 내고(재현성), 설명 가능한 규칙 기반(예측가능성)이다. Greedy, Beam search 알고리즘이 있다.
Random :
다양성(무작위성)을 강조하고, K값 또는 P값을 조정할 수 있는 유연성 있는 전략으로, Top-K, Top-P sampling 알고리즘이 있다.
위의 Greedy Search는 무엇이냐면,
각 시점에서 '확률이 가장 높은 단어 1개만' 선택하는 것이다.
빠르고 단순하며, 항상 동일한 결과가 나오게 된다. 하지만 전체적으로 봤을 때 최적이 아닌 결과가 나오기도 한다.

Beam Search는,
확률 상위 B개의 후보 Seq를 병렬로 유지한다.
B=3이면 3개의 후보를 생각하는 것! 이럼 다양한 후보를 고려해서 더 적절한 문장을 생성해낼 수 있다.
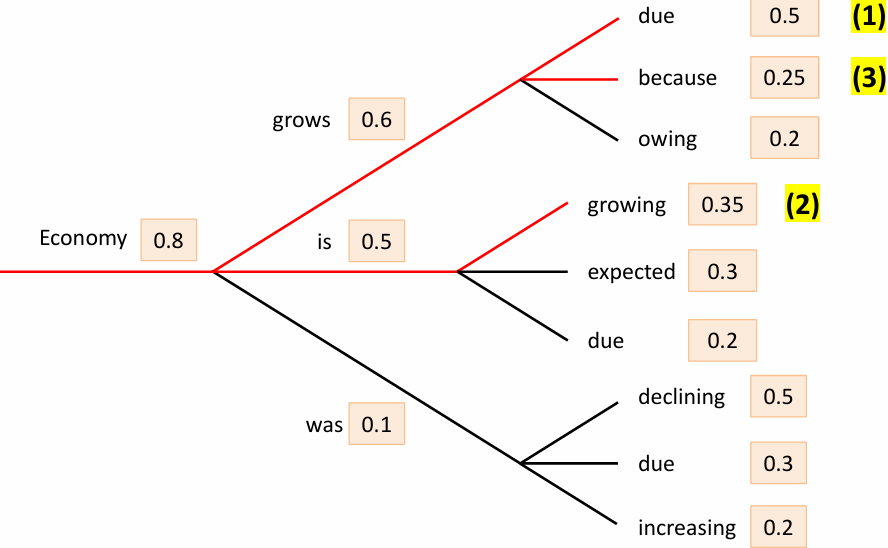
Random Sampling은,
Softmax를 통해 얻은 확률 분포를 그대로 사용하여 무작위로 다음 단어를 선택하는 방식이다.
확률이 높을수록 선택될 가능성이 높지만, 낮은 확률의 단어도 선택될 수 있다.
이럼 매우 다양한 결과를 생성할 수 있지만, 재현성이 없고 출력 품질이 들쑥날쑥할 수 있다.
Top-K Sampling
확률분포에서 상위 K개의 단어만 남기고 나머지를 제거한 후, 남은 단어의 확률을 재정규화 하여 진행하는 것이다.
이렇게 하면 다양성도 챙기고 재현성도 어느정도 챙길 수 있다.
또한 하위 확률 단어라면 거의 나올 일이 없는 단어인데, 그 단어들이 제거될 수 있다.
Top-P Sampling
이건 개수가 아닌 누적 확률로 따지는 방법이다. 가장 큰 확률부터 누적했을 때, 그 누적확률이 P를 넘어가기 전까지의 후보들만 선택지로 남기고 샘플링하는 것이다.
이는 Top-K보다 더 유연한 방법으로, 확률 분포에 따라 후보의 개수가 조절된다.
불확실성이 큰 상황에서 더 다양한 표현을 할 수 있게 된다.
Temperature

위의 확률 기반 샘플링과 비슷하다. 하지만 여기서는 확률에 T를 나누어 변형을 준다.
만약 T<1이라면, 작았던 확률과 컸던 확률간 차이가 더욱 많이 나게 되기에 보수적으로 작용하게 된다.
확률 분포의 차이가 확대되며 상위 후보가 더 강하게 선택되는 것이다. 높은 품질이 요구될 때 적합하다.
만약 T>1이라면, 확률 분포간 차이가 줄어들게 되며 평탄해진다.
따라서 하위 단어 선택 확률도 증가하게 되어 더 다양한 답변을 낼 수 있지만 위험성이 증가하게 된다.
창의성이 중요한 응용에 유리하지만, 불안정하거나 말이 안되는 문장이 나올 수도 있다.
Loss Function
Loss Function으로 자주 사용되는 Cross Entropy를 알아보겠다.

p(x)는 실제 정답, q(x)는 예측 확률이다. 보통 정답은 one-hot encoding으로 나타나므로 p(x)=1이다.
정답인 단어 위치의 확률이 높을수록 손실이 작아진다.
예를 들어 아래 그림을 보자.

파란 네모를 보면, 원래 grows를 예측해야 하는 곳인데 그 확률이 0.47이었고,
expands의 확률이 0.6으로 가장 컸기에 expands를 선택한 경우이다.
이때 정답인 grows의 p(x)=1이고, 예측된 expands의 prediction 확률인 q(x)=0.6이다.
따라서 이 CE는 실제로 예측한 정답 토큰의 확률이 얼마나 높았는지를 기준으로 평가하는 수치이다.
Evaluation
마지막 평가 단계이다.
NLP 모델의 출력 결과를 정량적으로 평가하는 방법을 소개한다.
대표적으로 ROUGE, BLEU 두 개의 지표가 있다.
ROUGE
Recall-Oriented Understudy for Gisting Evaluation
정답 문장과 예측 문장의 n-gram 겹치는 정도인 recall을 측정하는 것이다.
예를 들어,
정답 : Economy grows due to policies
예측 : Economy grows because of new policies
ROUGE-1(1-gram) : 3(공통 단어 개수)/5(Label 단어 개수)
ROUGE-2(2-gram) : 1(공통 두 단어 개수)/4(Label 두 단어 개수)
ROUGE-L(정답/예측 사이 최장 공통 부분 문자열 기반 계산, 이 예시에서는 L=2) : 1/4
BLEU
BiLingual Evaluation Understudy Score
정답과 예측의 n-gram Precision 기반 지표이다.
단어의 순서를 고려하며, 예측이 너무 짧을 경우 Brevity Penalty를 적용한다.
위와 같은 예시에서,
1-gram : 3(공통 단어 개수)/6(예측 단어 개수)
2-gram : 1(공통 두 단어 개수)/5(예측 두 단어 개수)
3-gram : 0
4-gram : 0
BLEU-4 : 1(BP) * (3/6 * 0.25 + 1/5 * 0/25 + 0 * 0.25 + 0 * 0.25) = 0.575
'AI > 자연어처리' 카테고리의 다른 글
| Vector DB, RAG (3) | 2025.06.15 |
|---|---|
| ChatGPT 학습 방법 (0) | 2025.06.14 |
| T5 model (3) | 2025.06.13 |
| AMP, Quantization (1) | 2025.06.13 |
| Big Neural Network Training Tricks (1) | 2025.06.12 |